
모든 네트워크 애플리케이션은 클라이언트-서버 모델을 기반으로 한다.
- 여기서 이야기하는 모델에 따르면, 애플리케이션은 한 개의 서버와 한 개 이상의 클라이언트로 구성된다.
- 서버는 특정 자원을 관리하고, 이 자원을 조작하여 클라이언트에게 서비스를 제공한다.
- 예를 들어, 웹 서버는 클라이언트를 대신하여 디스크 파일을 관리하고, 필요하면 해당 파일을 읽어서 실행한다.
- FTP 서버는 클라이언트를 위해 디스크 파일 집합을 저장하고 불러온다.
- 이메일 서버는 클라이언트를 위해 스풀 파일을 읽고 갱신하며 관리한다.
[그림 11.1]
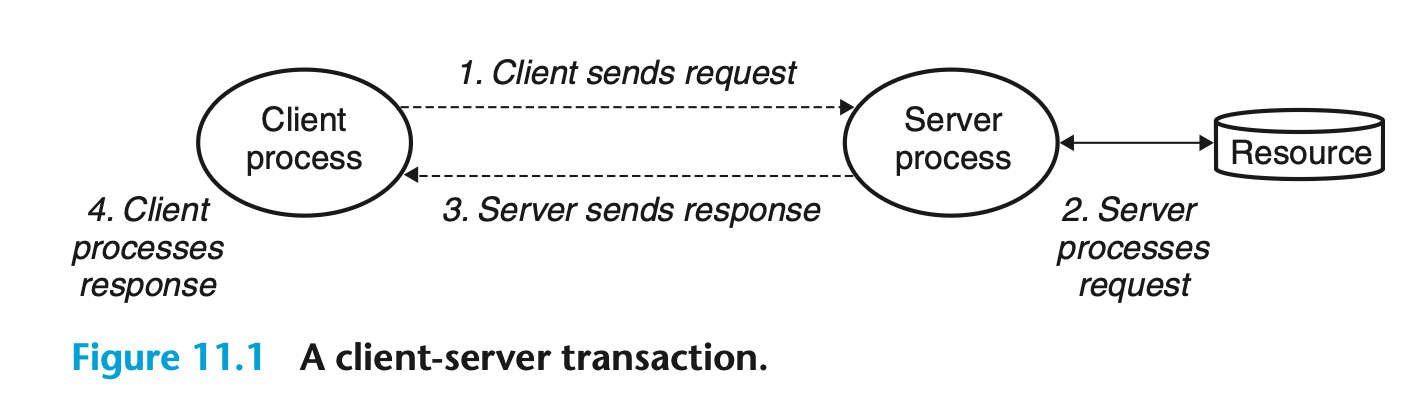
클라이언트-서버 모델의 기본 동작은 트랜잭션(그림 11.1)이다. 클라이언트-서버 트랜잭션은 네 가지 단계로 구성된다:
- 클라이언트가 서비스가 필요할 때, 서버에 요청을 보내어 트랜잭션을 시작한다.
- 예를 들어, 웹 브라우저가 파일을 필요로 할 때 웹 서버에 요청을 보낸다.
- 서버는 요청을 수신한 후, 이를 해석하고 적절한 방식으로 자원을 조작한다.
- 예를 들어, 웹 서버가 브라우저로부터의 요청을 받을 때 디스크 파일을 읽는다.
- 서버는 클라이언트에 응답을 보내고, 이후 다음 요청을 기다린다.
- 예를 들어, 웹 서버는 읽은 파일을 클라이언트에게 다시 보낸다.
- 클라이언트는 응답을 받아서 그것을 처리한다.
- 예를 들어 웹 브라우저가 서버로부터 페이지를 받은 후, 해당 페이지를 화면에 표시한다.
중요한 점은 클라이언트와 서버가 이 문맥에서 종종 머신이나 호스트라고 불리지만 실제로는 프로세스라는 것이다.
- 하나의 호스트에서 여러 서로 다른 클라이언트와 서버를 동시에 실행할 수 있다.
- 클라이언트와 서버 사이의 트랜잭션은 동일한 호스트에서 발생할 수도 있고 서로 다른 호스트에서 발생할 수도 있다.
- 클라이언트-서버 모델은 클라이언트와 서버의 호스트에 대한 매핑과 관계없이 동일하다.
클라이언트와 서버는 대개 별개의 호스트에서 실행되며, 컴퓨터 네트워크의 하드웨어 및 소프트웨어 자원을 활용하여 서로 통신한다. 네트워크는 매우 정교한 시스템이기 때문에, 여기에서는 그 일부만 다루어 본다. 우리의 목표는 프로그래머의 관점에서 이해할 수 있는 개념적 모델을 제공하는 것이다.
[그림 11.2]
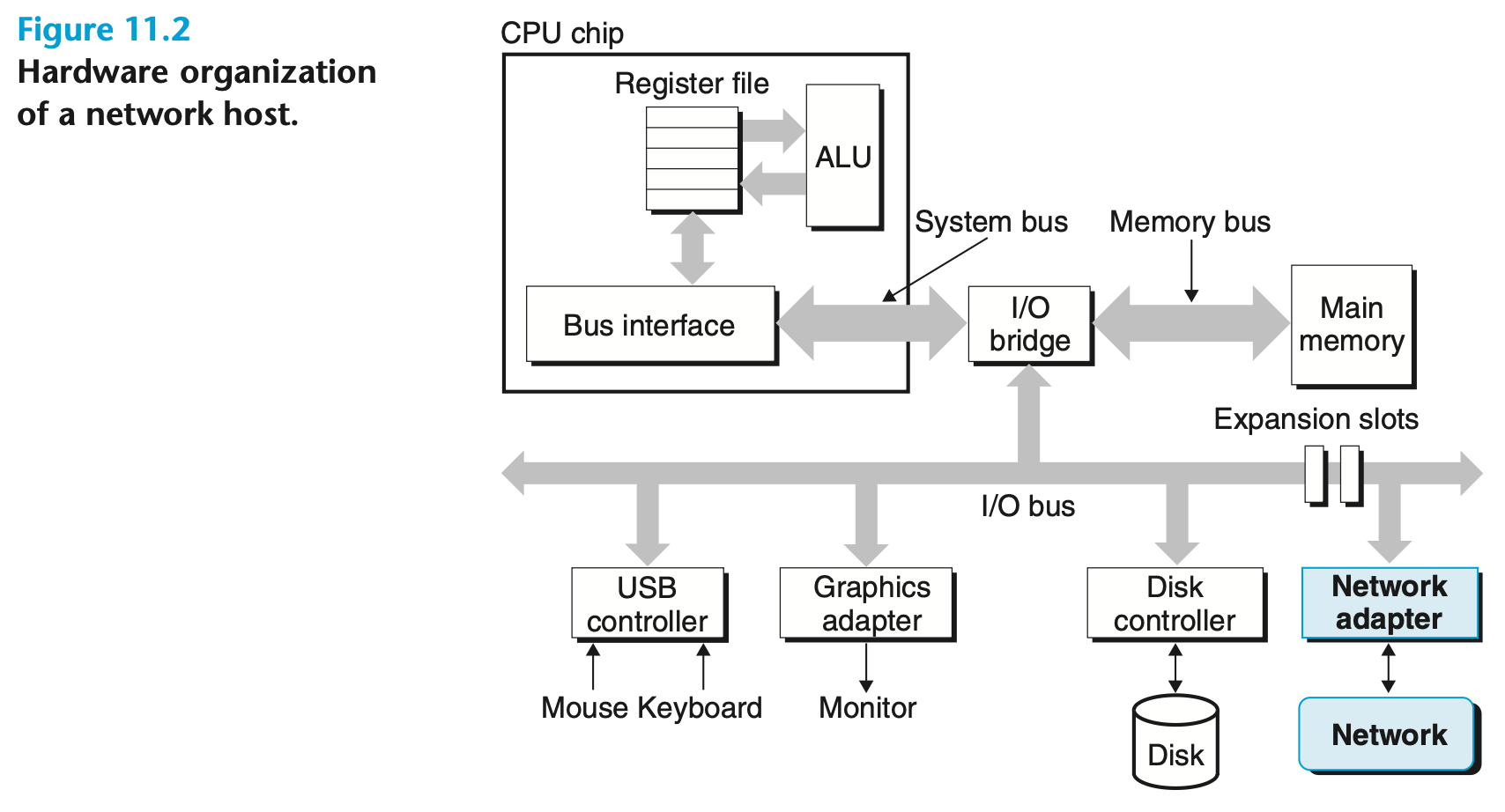
호스트에게 네트워크는 단지 데이터의 입출력(source and sink)을 담당하는 또 다른 I/O 장치일 뿐이며, 이는 그림 11.2에서와 같이 나타난다.
I/O 버스의 확장 슬롯에 꽂힌 어댑터는 네트워크와의 물리적 인터페이스를 제공한다.
- 네트워크로부터 수신된 데이터는 어댑터에서 I/O 버스와 메모리 버스를 거쳐 메모리로 복사되며, 일반적으로 DMA 전송에 의해 이루어진다. 유사하게, 데이터는 메모리에서 네트워크로도 복사될 수 있다.
네트워크는 물리적으로 지리적 근접성을 기준으로 조직된 계층적 시스템이다.
- 가장 낮은 수준에는 건물이나 캠퍼스를 아우르는 LAN(로컬 에리어 네트워크)이 있다.
- 지금까지 가장 대중적인 LAN 기술은 이더넷으로, 이는 1970년대 중반 Xerox PARC에서 개발되었다.
- 이더넷은 놀라울 정도로 탄력성을 보이며, 3 Mb/s에서 10 Gb/s로 발전해왔다.
[그림 11.3]
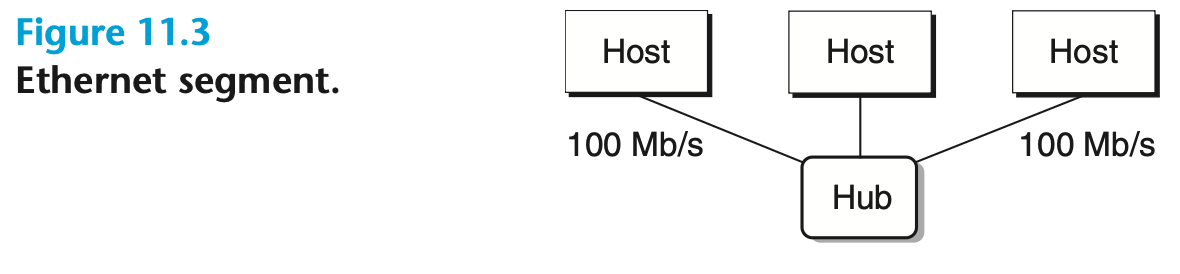
이더넷 세그먼트는 그림 11.3에 나타난 바와 같이, 일반적으로 꼬인 쌍의 케이블(와이어)과 ‘허브’라고 불리는 작은 박스로 구성된다.
- 이더넷 세그먼트는 보통 방이나 건물의 한 층처럼 제한된 영역을 아우른다.
- 각 선은 동일한 최대 비트 전송 대역폭(일반적으로는 100 Mb/s 또는 1 Gb/s)을 가진다.
- 한쪽 끝은 호스트에 있는 어댑터에, 다른 한쪽 끝은 허브의 포트에 연결된다.
- 허브는 각 포트에서 수신한 모든 비트를 다른 모든 포트로 그대로 복사하므로, 네트워크에 연결된 모든 호스트가 모든 비트를 보게 된다.
각 이더넷 어댑터는 어댑터의 비휘발성 메모리에 저장된 전 세계적으로 유일한 48비트 주소를 가진다.
(이것을 우리가 흔히 들어본 MAC 주소라고들 한다)
- 호스트는 세그먼트 내의 다른 호스트에게 ‘프레임’이라고 불리는 비트 묶음을 전송할 수 있다.
- 각 프레임은 출발지와 목적지, 프레임 길이를 식별하는 고정된 수의 header bits, 그 뒤를 잇는 데이터 비트들의 payload로 구성된다.모든 호스트 어댑터는 프레임을 감지하지만, 실제로 내용을 읽는 것은 오직 목적지 호스트뿐이다.
목적지로 지정된 장치가 아니어도 패킷을 감지 할 수는 있다고 하셨습니다. 그럼 그런 감지가 trigger가 되는 코드를 목적지가 아닌 장치 입장에서 작동시킬 수 있는 것입니까?
네, 물리적으로 이더넷 어댑터는 네트워크 상의 모든 프레임을 “감지”할 수 있습니다. 하지만 일반적으로 운영체제의 네트워크 스택이나 드라이버는 하드웨어가 수신한 모든 데이터를 그대로 코드에 전달하지 않고, 자신의 MAC 주소나 브로드캐스트 주소와 일치하는 패킷만을 처리하도록 되어 있습니다.
따라서, 기본 상태에서는 목적지가 아닌 호스트에서 들어오는 패킷을 감지한다고 해도, 그 패킷이 운영체제나 응용 프로그램에 의해 "읽혀져" 코드 실행의 트리거로 사용되지는 않습니다.
만약 의도적으로 다른 호스트로 향하는 패킷을 포함해 모든 패킷을 처리하고 싶다면, 네트워크 인터페이스를 프로미스큐어스(promiscuous) 모드로 전환해야 합니다. 이 모드에서 NIC는 수신한 모든 패킷을 운영체제에 전달하게 되며, 이를 바탕으로 패킷 스니핑, 네트워크 모니터링, 또는 특정 조건에 따라 코드를 실행하는 응용 프로그램(예: IDS/IPS, 트래픽 분석 도구) 등을 구현할 수 있습니다.
[그림 11.4]

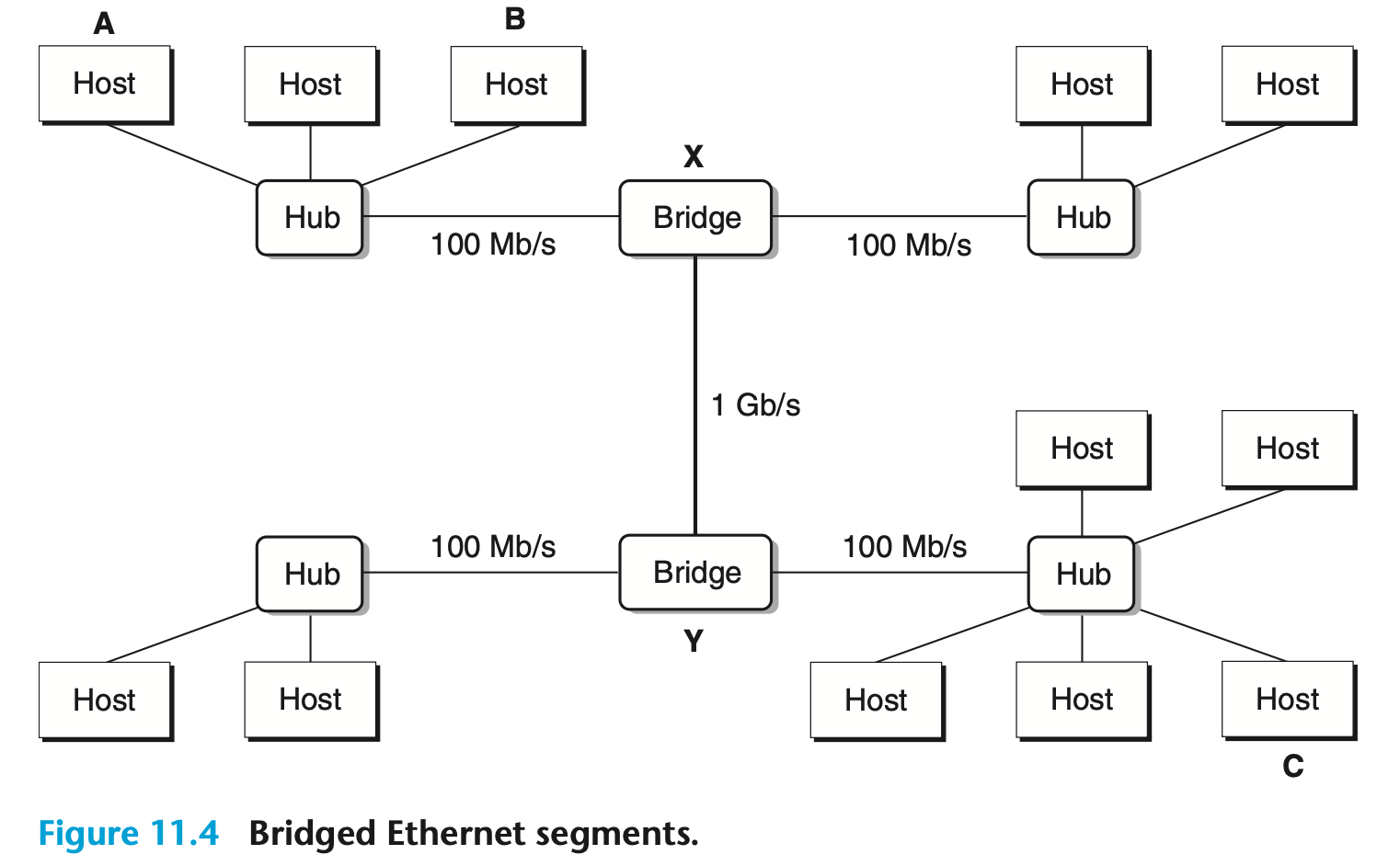
여러 이더넷 세그먼트를 여러 개의 케이블과 ‘브리지’라는 작은 박스를 사용하여 연결해보자.
- 여긴 Layer 2, 데이터 링크 계층에 대해 다루는 영역이다.
- 그림 11.4와 같이 브리지드 이더넷(bridged Ethernet)이라고 불리는 더 큰 LAN을 구성할 수 있다.
- 브리지드 이더넷은 건물 전체나 캠퍼스 전체를 아우를 수 있다.
건물 전체나 캠퍼스 전체가 너무 추상적인 개념이 아닌가요?
네트워크 시스템을 설명할 때 "캠퍼스 단위"라는 표현을 사용하는 것은 일반적인 개념적 추상화입니다. 대학마다 캠퍼스의 크기와 네트워크 구조가 다를 수 있지만, 브리지드 이더넷의 개념은 단일 건물뿐만 아니라 여러 개의 건물이 연결된 캠퍼스 전체에도 적용될 수 있습니다.
이러한 추상화는 네트워크의 범위를 설명할 때 일반적인 조직 단위를 나타내는 용어로 사용됩니다. 즉, 특정 대학의 물리적 크기와 관계없이, "캠퍼스 네트워크"라는 용어는 다수의 건물과 세그먼트가 연결된 환경을 의미하는데 편리하게 활용될 수 있습니다. 이는 기업, 공장, 스마트 빌딩 등에서도 유사하게 적용됩니다.
따라서 "캠퍼스 단위로 묶인다"는 표현은 개별적인 네트워크 세그먼트가 브리지드 이더넷을 통해 통합될 수 있다는 개념을 나타내는 일반적인 용어이며, 반드시 모든 대학이 동일한 규모나 구성일 필요는 없습니다.
- 브리지드 이더넷에서 일부 케이블은 브리지를 브리지에 연결하고, 다른 케이블은 브리지를 허브에 연결한다. 이때 각 케이블의 대역폭은 서로 다를 수 있다.
- 예를 들어, 본 예시에서는 브리지 간 연결선은 1 Gb/s의 대역폭을 가지는 반면, 네 개의 허브–브리지 연결선은 각각 100 Mb/s의 대역폭을 가진다.
브리지는 허브보다 사용 가능한 케이블 대역폭을 더욱 효율적으로 활용한다. 브리지는 독창적인 분산 알고리즘을 사용한다.
- 시간이 지남에 따라 각 포트에서 도달 가능한 호스트를 자동으로 학습한다.
- 이 학습된 내용을 기반해서, 프레임을 한 포트에서 다른 포트로 복사할 때 꼭 필요한 경우에만 선택적으로 전송한다.
뭐 얼마나 독창적이길래 브리지 단독입니까? 허브는 그런 것을 사용 할 수 없습니까?
네. 브리지의 독창적인 알고리즘은 허브에서 사용이 불가능합니다. 허브뿐만 아니라 현실적으로 더 빠르게 하기엔 벽에 부딪히는 상황이었기에, 사장되어가는 기술이고 아직 소수의 영역에서만 남아있습니다. 허브 영역의 처리 속도를 빠르게 하기 위해 네트워크 스위치라는 장치가 등장했고, 스위치에서 브리지까지 구현 가능한 영역까지가 현대 시대에 통용되는 네트워크 기술이라 할 수 있습니다.
[예를 들어]
- 호스트 A가 동일 세그먼트 내의 호스트 B에게 프레임을 전송한다.
- 브리지 X는 해당 프레임이 입력 포트에 도착하는 순간 폐기하여 다른 세그먼트의 대역폭을 절약한다.
- 반면, 호스트 A가 다른 세그먼트에 위치한 호스트 C에게 프레임을 전송한다.
- 브리지 X는 그 프레임을 브리지 Y에 연결된 포트로만 복사하고, 브리지 Y는 다시 해당 프레임을 호스트 C의 세그먼트와 연결된 포트로만 복사한다.
[그림 11.5]
- 여긴 Layer 3, 네트워크 계층에 대해 다루는 영역이다.
- 계층 구조의 더 높은 수준에서는, 서로 호환되지 않는 여러 LAN들을 라우터라는 특수한 컴퓨터로 연결하여 인터넷(상호 연결된 네트워크)을 구성할 수 있다.
- 각 라우터는 자신이 연결된 각 네트워크에 대해 어댑터(포트)를 갖추고 있다.
- 또한 라우터는 LAN보다 훨씬 넓은 지리적 영역을 아우르는 WAN(광역 네트워크)으로 알려진 고속 point to point 전화 연결도 연결 할 수 있다.
- 일반적으로, 라우터는 임의의 LAN과 WAN의 모음으로부터 인터넷을 구축하는 데 사용되고 있다.
- 예를 들어, 그림 11.6은 세 개의 라우터로 연결된 한 쌍의 LAN과 WAN이 있는 인터넷의 예를 보여주고 있다.
[그림 11.6]

인터넷의 가장 중요한 특성은 서로 극도로 다르고 호환되지 않는 기술들을 사용하는 다양한 LAN과 WAN으로 구성될 수 있다는 점이다.
- 각 호스트가 물리적으로 모든 다른 호스트와 연결되어 있음에도, 어떻게 한 출발지 호스트가 이 모든 서로 다른 네트워크를 넘어 다른 목적지 호스트로 데이터 비트를 전송 할 수 있다.
- 해결책은 각 호스트와 라우터에서 실행되는 프로토콜 소프트웨어 계층에 있다. 이 소프트웨어는 서로 다른 네트워크 간의 차이를 완화시키는 역할을 하며, 호스트와 라우터가 데이터 전송을 위해 협력하는 방법을 규정하는 프로토콜을 구현한다. 이 프로토콜은 두 가지 기본 기능을 제공한다.
명명 체계 (Naming scheme)
- 서로 다른 LAN 기술은 호스트에 주소를 할당하는 방식이 모두 다르고 서로 호환되지 않는다.
- 인터넷 프로토콜은 이러한 차이를 해소하기 위해 호스트 주소에 대해 균일한 형식을 정의하게 된다.
- 따라서 각 호스트는 자신을 고유하게 식별할 수 있는 하나 이상의 인터넷 주소가 할당된다.
전달 메커니즘 (Delivery mechanism)
- 네트워크 기술마다 와이어 위의 비트를 인코딩하는 방식이나 이 비트를 프레임에 패키징하는 방식이 서로 다르고 호환되지 않는다.
- 인터넷 프로토콜은 데이터를 “패킷”이라는 분리된 청크로 묶는 균일한 방법을 정의하여 이러한 차이를 해소한다.
- 하나의 패킷은 헤더와 페이로드로 구성되며, 헤더에는 패킷의 크기와 출발지 및 목적지 호스트의 주소가 포함되고, 페이로드에는 출발지 호스트에서 전송된 데이터 비트들이 포함된다.
[그림 11.7]
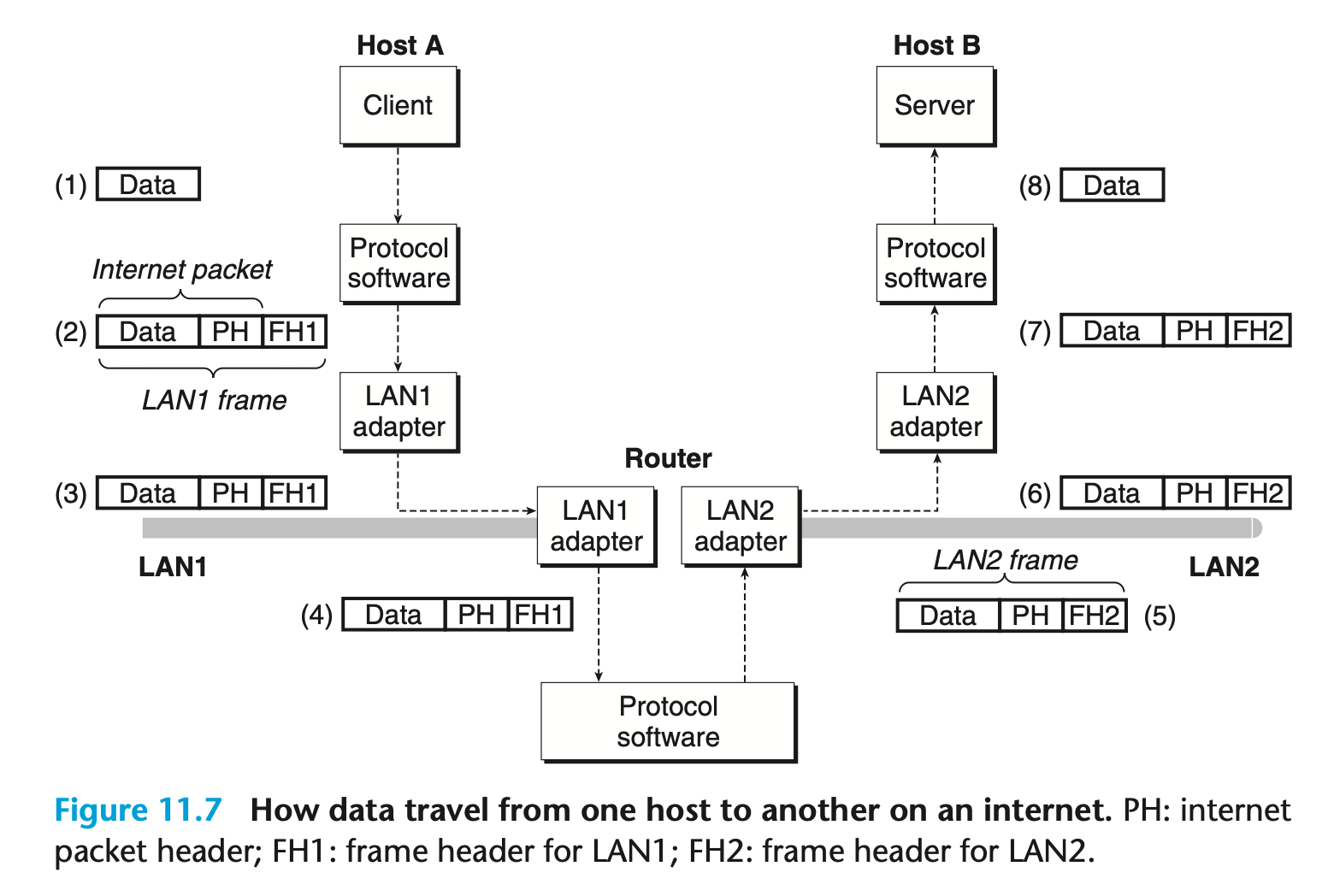
그림 11.7은 호스트와 라우터가 어떻게 서로 호환되지 않는 LAN들 간에 인터넷 프로토콜을 사용하여 데이터를 전송하는지를 보여주는 예시이다.
이 예제 인터넷은 라우터로 연결된 두 개의 LAN으로 구성된다. LAN1에 연결된 호스트 A에서 실행 중인 클라이언트가, LAN2에 연결된 호스트 B에서 실행 중인 서버로 데이터 바이트들의 시퀀스를 전송한다. 기본적으로 다음과 같은 8가지 단계로 이루어진다 :
- 호스트 A의 클라이언트는 시스템 호출을 실행하여 클라이언트의 가상 주소 공간에 있는 데이터를 커널 버퍼로 복사한다.
- 호스트 A의 프로토콜 소프트웨어는 데이터를 기반으로 인터넷 헤더와 LAN1 프레임 헤더를 덧붙여 LAN1 프레임을 생성한다. 이때, 인터넷 헤더는 인터넷 호스트 B를 대상으로 하고, LAN1 프레임 헤더는 라우터를 대상으로 한다. 이후, 이 프레임은 어댑터로 전달된다. 주목할 점은, LAN1 프레임의 페이로드가 인터넷 패킷인데, 그 내부 페이로드가 실제 사용자 데이터라는 것이다. 이러한 캡슐화(encapsulation) 방식은 인터넷워킹의 근본적인 통찰 중 하나이다.
- LAN1 어댑터는 프레임을 네트워크로 복사한다.
- 프레임이 라우터에 도착하면, 라우터의 LAN1 어댑터가 선(와이어)에서 프레임을 읽어 프로토콜 소프트웨어로 전달한다.
- 라우터는 인터넷 패킷 헤더에서 목적지 인터넷 주소를 추출한 후, 이를 인덱스로 사용하여 라우팅 테이블에서 패킷을 어디로 전달할지 결정한다. 이 경우 대상은 LAN2이다. 그런 다음 라우터는 기존의 LAN1 프레임 헤더를 제거하고, 호스트 B를 대상으로 하는 새로운 LAN2 프레임 헤더를 덧붙인 후, 결과 프레임을 어댑터에 전달한다.
- 라우터의 LAN2 어댑터는 프레임을 네트워크로 복사한다.
- 프레임이 호스트 B에 도착하면, 호스트 B의 어댑터가 선에서 프레임을 읽어 프로토콜 소프트웨어로 전달한다.
- 마지막으로, 호스트 B의 프로토콜 소프트웨어가 패킷 헤더와 프레임 헤더를 제거한다. 이후 서버가 데이터를 읽기 위해 시스템 호출을 실행하면, 프로토콜 소프트웨어는 최종적으로 결과 데이터를 서버의 가상 주소 공간으로 복사한다.
물론, 여기서는 서로 다른 네트워크의 최대 프레임 크기가 다를 경우, 라우터가 프레임을 어디로 전달해야 하는지 판단하는 방법, 네트워크 토폴로지가 변경될 때 라우터에 어떻게 통보되는지, 또는 패킷이 손실될 경우 등의 많은 어려운 문제들을 간략하게 다루고 있다.
그럼에도 불구하고, 우리의 예시는 인터넷 개념의 본질, 즉 캡슐화(encapsulation)가 핵심임을 잘 보여준다.
11.3 The Global IP Internet
[그림 11.8]
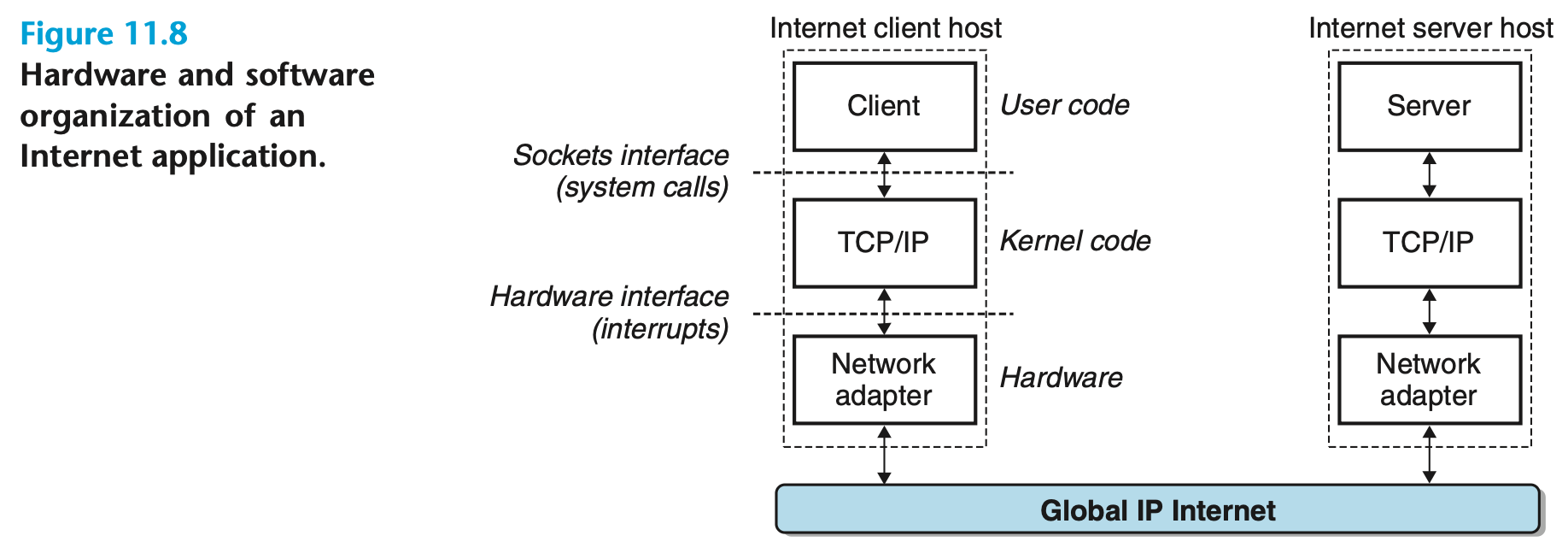
- 비록 인터넷의 내부 아키텍처는 복잡하고 끊임없이 변화하고 있다.
- 그렇지만, 클라이언트-서버 애플리케이션의 구성은 1980년대 초반 이후로 놀랄 만큼 안정적으로 유지되어 왔다.
- 그림 11.8은 인터넷 클라이언트-서버 애플리케이션의 기본 하드웨어 및 소프트웨어 구성을 보여준다.
각 인터넷 호스트는 거의 모든 현대 컴퓨터 시스템에서 지원하는 TCP/IP 프로토콜(전송 제어 프로토콜/인터넷 프로토콜)을 구현하는 소프트웨어를 실행한다.
- 인터넷 클라이언트와 서버는 소켓 인터페이스 함수와 유닉스 I/O 함수의 조합을 사용하여 통신한다. (소켓은 이후 11.4에서 설명한다.)
- 이 소켓 함수들은 일반적으로 시스템 호출로 구현되어 커널로 진입한 후, TCP/IP의 커널 모드 함수들을 호출한다.
TCP/IP는 사실 여러 프로토콜이 모여 이루어진 패밀리이며, 각 프로토콜은 서로 다른 기능을 제공한다. 예를 들어,
- IP는 기본적인 명명 체계와 한 인터넷 호스트에서 다른 호스트로 데이터그램(datagram)이라고 불리는 패킷을 전송할 수 있는 전송 메커니즘을 제공한다.
IP 메커니즘은 네트워크에서 데이터그램이 손실되거나 중복되어도 복구를 시도하지 않으므로 신뢰성이 떨어진다고 볼 수 있다.
- UDP(비신뢰적 데이터그램 프로토콜)는 IP 위에 약간의 확장을 더해 데이터그램이 호스트 간이 아니라 프로세스 간에 전송될 수 있게 한다.
- TCP는 IP 위에 구축되어 프로세스 간에 신뢰할 수 있는 전이중(양방향) 연결을 제공하는 복잡한 프로토콜이다.
- 여기서는 논의를 단순화하기 위해 TC/IP를 하나의 모놀리식 프로토콜로 취급할 것이다.
내부 동작 방식에 대해서는 다루지 않고, TCP와 IP가 애플리케이션 프로그램에 제공하는 기본 기능 몇 가지만 논의할 것이다.
- UDP에 대해서는 다루지 않을 것이다.
프로그래머의 관점에서 보면, 인터넷은 아래와 같은 특성을 지닌 전 세계의 호스트 모음으로 생각할 수 있다:
- 호스트 집합은 32비트 IP 주소 집합으로 매핑된다.
- IP 주소 집합은 인터넷 도메인 이름(Internet domain names)이라는 식별자 집합으로 매핑된다.
- 한 인터넷 호스트의 프로세스는 연결을 통해 다른 인터넷 호스트의 프로세스와 통신할 수 있다.
다음 섹션에서는 이러한 인터넷의 기본 개념을 더 자세히 논의한다.
11.3.1 IP 주소들
[그림 11.9]

IP 주소는 부호 없는 32비트 정수이다. 네트워크 프로그램들은 그림 11.9에 나타난 IP 주소 구조체에 IP 주소를 저장하고 사용한다. 스칼라 주소를 구조체에 저장하는 것은 소켓 인터페이스 초기 구현 시절의 참 구린 유산이다.
- IP 주소를 위한 스칼라 타입을 정의하는 것이 더 합리적이었겠지만, 이미 방대한 양의 애플리케이션이 설치되어 있어 지금 바꾸기는 너무 늦긴 했다.
인터넷을 사용하고자 하는 장치마다 바이트 오더 기준을 가질 수 있다.
- TCP/IP는 IP 주소와 같은 정수형 데이터가 패킷 헤더를 통해 네트워크로 전달될 때 균일한 네트워크 바이트 오더를 사용하도록 정의한다.
- 따라서 IP 주소 구조체 내의 주소들은 호스트의 바이트 오더가 리틀 엔디언일지라도 항상 (빅 엔디언) 네트워크 바이트 오더로 저장된다.
- Unix는 네트워크와 호스트 바이트 오더 간의 변환을 위해 다음과 같은 함수를 제공한다.
#include <arpa/inet.h> uint32_t htonl(uint32_t hostlong); uint16_t htons(uint16_t hostshort); // Returns: value in network byte order uint32_t ntohl(uint32_t netlong); uint16_t ntohs(unit16_t netshort); // Returns: value in host byte order- htonl 함수는 부호 없는 32비트 정수를 호스트 바이트 오더에서 네트워크 바이트 오더로 변환한다.
- ntohl 함수는 네트워크 바이트 오더에서 호스트 바이트 오더로 부호 없는 32비트 정수를 변환한다.
- htons와 ntohs 함수는 부호 없는 16비트 정수에 대해 각각 대응하는 변환을 수행한다.
- 참고로, 64비트 값에 대한 변환 함수는 제공되지 않는다.
IP 주소는 일반적으로 도트-십진법 표기법(dotted-decimal notation)으로 사람들에게 표시된다.
- 이 표기법에서는 각 바이트를 해당하는 십진수 값으로 표현하고, 다른 바이트들과는 점(.)으로 구분하고 있다.
- 예를 들어,
128.2.194.242는 주소0x8002c2f2의 도트-십진법 표현이다. - Linux 시스템에서는 자신의 호스트의 도트-십진법 주소를 확인하기 위해
hostname명령어를 사용할 수 있다.
linux> hostname -i
128.2.210.175
응용 프로그램은 inet_pton과 inet_ntop 함수를 사용하여 IP 주소와 도트-십진법 문자열 간을 상호 변환 할 수 있다.
#include <arpa/inet.h>
int inet_pton(AF_INET, const char *src, void *dst);
// Returns: 1 if OK, 0 if src is invalid dotted decimal,−1 on error
const char *inet_ntop(AF_INET, const void *src, char *dst, socklen_t size);
// Returns: pointer to a dotted-decimal string if OK, NULL on error- 이 함수 이름에서 "n"은 network(네트워크)를, "p"는 presentation(표현)을 의미한다.
- 이 함수들은 여기서 다루는 32비트 IPv4 주소(AF_INET)뿐만 아니라, 우리가 다루지 않는 128비트 IPv6 주소(AF_INET6)도 처리할 수 있다.
- inet_pton 함수는 도트-십진법 문자열(
src)을 네트워크 바이트 오더의 이진 IP 주소(dst)로 변환한다.- inet_ntop 함수는 네트워크 바이트 오더의 이진 IP 주소(
src)를 대응하는 도트-십진법 표현으로 변환한 후, 결과로 얻은 null 종료 문자열을 최대size바이트까지dst에 복사한다. - 만약
src가 유효한 도트-십진법 문자열(또는 이진 IP 주소)을 가리키지 않는다면, 이 함수는 0을 반환한다. - 그 외의 오류가 발생하면 -1을 반환하며,
errno를 설정한다.
- inet_ntop 함수는 네트워크 바이트 오더의 이진 IP 주소(
11.3.2 인터넷 도메인 이름
인터넷 클라이언트와 서버는 서로 통신할 때 IP 주소를 사용한다.
하지만 길기도 하고, 그냥 보면 딱히 규칙적이지도 않은 이 긴 정수는 사람들이 기억하기 어렵다.
- 이를 해결하기 위해 인터넷은 사람에게 친숙한 도메인 이름 집합과, 이 도메인 이름 집합을 IP 주소 집합에 매핑하는 메커니즘을 별도로 정의한다.
- 도메인 이름은 점(.)으로 구분된 단어(문자, 숫자, 그리고 대시)들의 나열로 구성되며, 예를 들어
whaleshark.ics.cs.cmu.edu와 같은 형태이다.
도메인 이름 집합은 계층 구조를 형성하며, 각 도메인 이름은 그 계층 내에서의 위치를 암시한다. 가장 쉽게 이해할 수 있는 예가 바로 이것이다.
[그림 11.10]
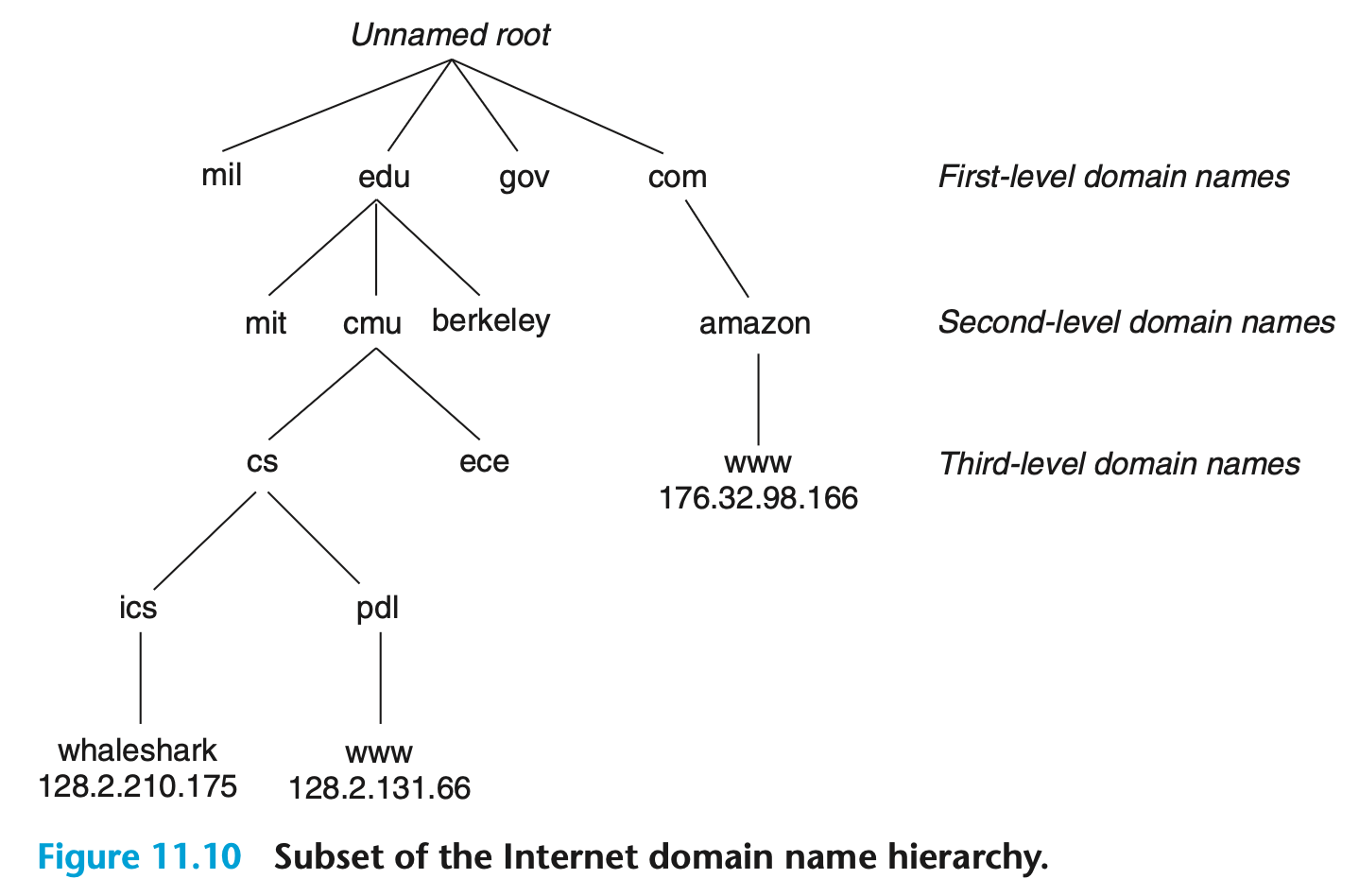
- 그림 11.10은 도메인 이름 계층 구조의 일부를 보여준다.
- 이 계층 구조는 트리로 표현되며, 트리의 각 노드는 루트로 거슬러 올라가는 경로에 의해 형성된 도메인 이름을 나타낸다.
- 트리의 하위 트리는 하위 도메인(subdomains)이라고 불린다.
- 계층 구조의 첫 번째 레벨은 이름이 없는 루트 노드이고, 그 다음 레벨은 ICANN(Internet Corporation for Assigned Names and Numbers)이라는 비영리 단체에 의해 정의된 1차 도메인 이름들의 집합이다. 일반적으로 사용되는 1차 도메인으로는
com,edu,gov,org,net등이 있다.
다음 레벨에는 cmu.edu와 같은 2차 도메인 이름들이 있으며, 이는 ICANN의 권한을 위임받은 다양한 대리인들이 선착순에 따라 할당한다.
- 한 조직이 2차 도메인 이름을 할당받으면, 그 하위 도메인 내에서
cs.cmu.edu와 같이 새로운 도메인 이름을 자유롭게 생성할 수 있다. - 인터넷은 도메인 이름 집합과 IP 주소 집합 간의 매핑을 정의한다. 1988년까지 이 매핑은
HOSTS.TXT라는 단일 텍스트 파일에 수동으로 관리되었다.- 그 이후부터, DNS(Domain Name System)라는 전 세계에 분산된 데이터베이스에 의해 관리되고 있다.
- 개념적으로, DNS 데이터베이스는 수백만 개의 호스트 엔트리로 구성되며, 각 엔트리는 도메인 이름 집합과 IP 주소 집합 사이의 매핑을 정의한다. 수학적으로 보면, 각 호스트 엔트리를 도메인 이름과 IP 주소의 동치류(equivalence class)로 생각할 수 있다. Linux의
nslookup프로그램을 사용하면, 도메인 이름에 연관된 IP 주소들을 확인하며 DNS 매핑의 몇 가지 속성을 살펴볼 수 있다.
각 인터넷 호스트는 로컬에서 정의된 도메인 이름인 localhost를 가지며, 이는 항상 루프백 주소 127.0.0.1에 매핑된다:
linux> nslookup localhost
Address: 127.0.0.1localhost 이름은 같은 기계에서 실행 중인 클라이언트와 서버를 참조하는 편리하고 이식 가능한 방법을 제공하며, 이는 디버깅 시 특히 유용하다.
또한, hostname 명령어를 사용하여 로컬 호스트의 실제 도메인 이름을 확인할 수 있다:
linux> hostname
whaleshark.ics.cs.cmu.edu가장 단순한 경우에는 도메인 이름과 IP 주소 사이에 일대일 매핑이 존재한다:
linux> nslookup whaleshark.ics.cs.cmu.edu
Address: 128.2.210.175그러나 어떤 경우에는 여러 도메인 이름이 동일한 IP 주소에 매핑될 수도 있다:
linux> nslookup cs.mit.edu
Address: 18.62.1.6
linux> nslookup eecs.mit.edu
Address: 18.62.1.6가장 일반적인 경우로, 여러 도메인 이름들이 여러 IP 주소 집합에 매핑될 수도 있다:
linux> nslookup www.twitter.com
Address: 199.16.156.6
Address: 199.16.156.70
Address: 199.16.156.102
Address: 199.16.156.230
linux> nslookup twitter.com
Address: 199.16.156.102
Address: 199.16.156.230
Address: 199.16.156.6
Address: 199.16.156.70마지막으로, 일부 유효한 도메인 이름은 어떠한 IP 주소에도 매핑되지 않는 경우도 있다:
linux> nslookup edu
*** Can’t find edu: No answer
linux> nslookup ics.cs.cmu.edu
*** Can’t find ics.cs.cmu.edu: No answer11.3.3 인터넷 연결
인터넷 클라이언트와 서버는 연결을 통해 바이트 스트림을 주고받으면서 통신한다.
- 이 연결은 한 쌍의 프로세스를 연결한다는 점에서 일대일(point-to-point) 연결이다.
- 동시에 양방향으로 데이터가 흐를 수 있는 전이중(full duplex) 통신이다.
- 케이블이 우연히 끊어지는 등의 극단적 실패(예: 부주의한 굴착기 작업으로 인한 케이블 끊김)가 발생하지 않는 한, 송신 프로세스에서 보낸 바이트 스트림이 전송된 순서대로 결국 수신 프로세스에 도착하는 신뢰성(reliable)을 가진다.
소켓(socket)은 연결의 끝점(end point)이다.
- 각 소켓은 인터넷 주소와 16비트 정수 포트로 구성된 해당 소켓 주소(socket address)를 가지며, 보통
address:port형식으로 표기된다.
클라이언트 소켓 주소에 있는 포트는 클라이언트가 연결 요청을 할 때 커널에 의해 자동으로 할당되며, 이를 임시 포트(ephemeral port)라고 한다.
- 반면에, 서버 소켓 주소의 포트는 보통 해당 서비스와 영구적으로 연관된 잘 알려진 포트(well-known port)이다.
- 예를 들어, 웹 서버는 보통 포트 80을 사용하고, 이메일 서버는 포트 25를 사용한다.
- 각 잘 알려진 포트에 대응하는 서비스에는 관련된 잘 알려진 서비스 이름도 있다.
- 예를 들어, 웹 서비스의 잘 알려진 이름은
http이며, 이메일은smtp이다. - 잘 알려진 이름과 포트 간의 매핑 정보는
/etc/services파일에 포함되어 있다.
- 예를 들어, 웹 서비스의 잘 알려진 이름은
연결은 양 끝점의 소켓 주소에 의해 유일하게 식별된다. 이 소켓 주소의 쌍은 소켓 페어(socket pair)라고 하며, 다음과 같은 튜플로 표기된다: (cliaddr:cliport, servaddr:servport)
- 여기서
cliaddr은 클라이언트의 IP 주소,cliport는 클라이언트의 포트,servaddr은 서버의 IP 주소,servport는 서버의 포트를 의미한다.
예를 들어, 그림 11.11은 웹 클라이언트와 웹 서버 간의 연결을 보여준다.
[그림 11.11]
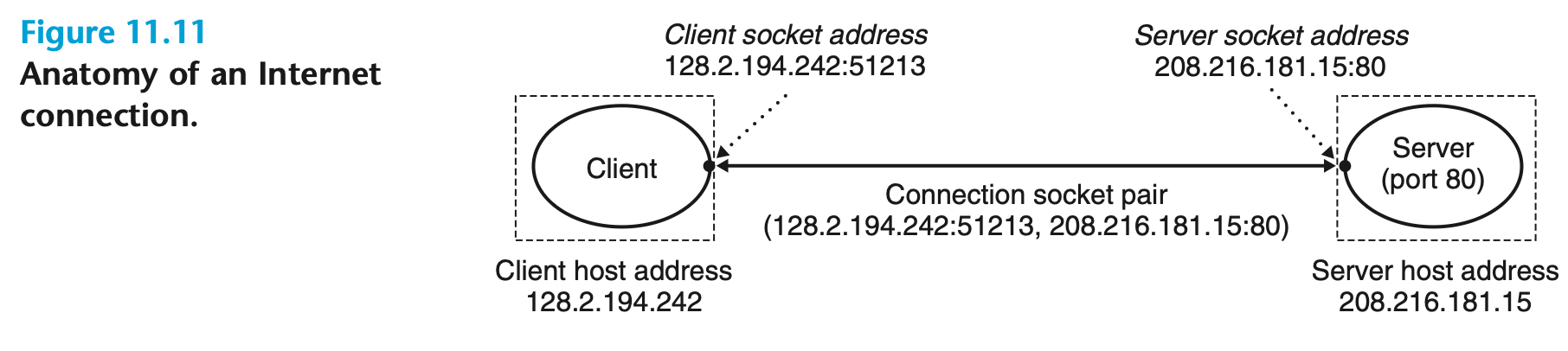
이 예에서 웹 클라이언트의 소켓 주소는 128.2.194.242:51213이며, 여기서 포트 51213은 커널에 의해 할당된 임시 포트이다.
웹 서버의 소켓 주소는 208.216.181.15:80이며, 여기서 포트 80은 웹 서비스와 연관된 잘 알려진 포트이다.
따라서, 클라이언트와 서버의 소켓 주소를 통해 연결은 소켓 페어 (128.2.194.242:51213, 208.216.181.15:80)로 고유하게 식별된다.
11.4 소켓 인터페이스
[그림 11.12]
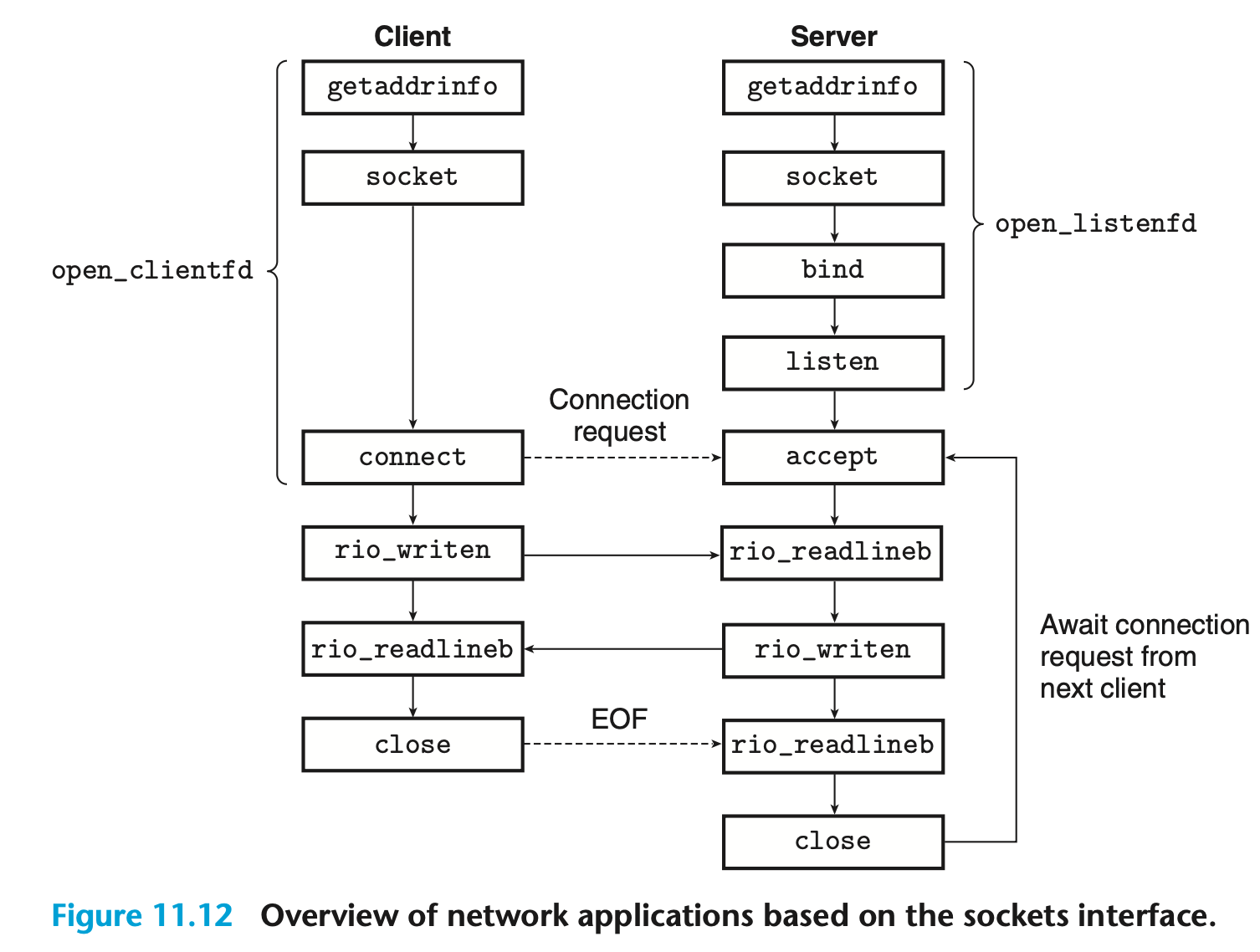
소켓 인터페이스는 유닉스 I/O 함수와 함께 네트워크 애플리케이션을 구축하기 위해 사용되는 일련의 함수들이다.
이 인터페이스는 모든 유닉스 계열 시스템은 물론 윈도우와 매킨토시 시스템 등 대부분의 최신 시스템에 구현되어 있다.
그림 11.12는 전형적인 클라이언트-서버 트랜잭션 상황에서 소켓 인터페이스의 개요를 보여주고 있다. 이후 개별 함수들에 대해 설명할 때 이 그림을 로드맵으로 삼으면 도움이 된다.
11.4.1 소켓 주소 구조체
리눅스 커널의 관점에서 소켓은 통신을 위한 끝점(end point)이다.
- 반면, 리눅스 프로그램의 관점에서는 소켓은 해당하는 파일 디스크립터를 가진 열린 파일(open file)이다.
[그림 11.13]
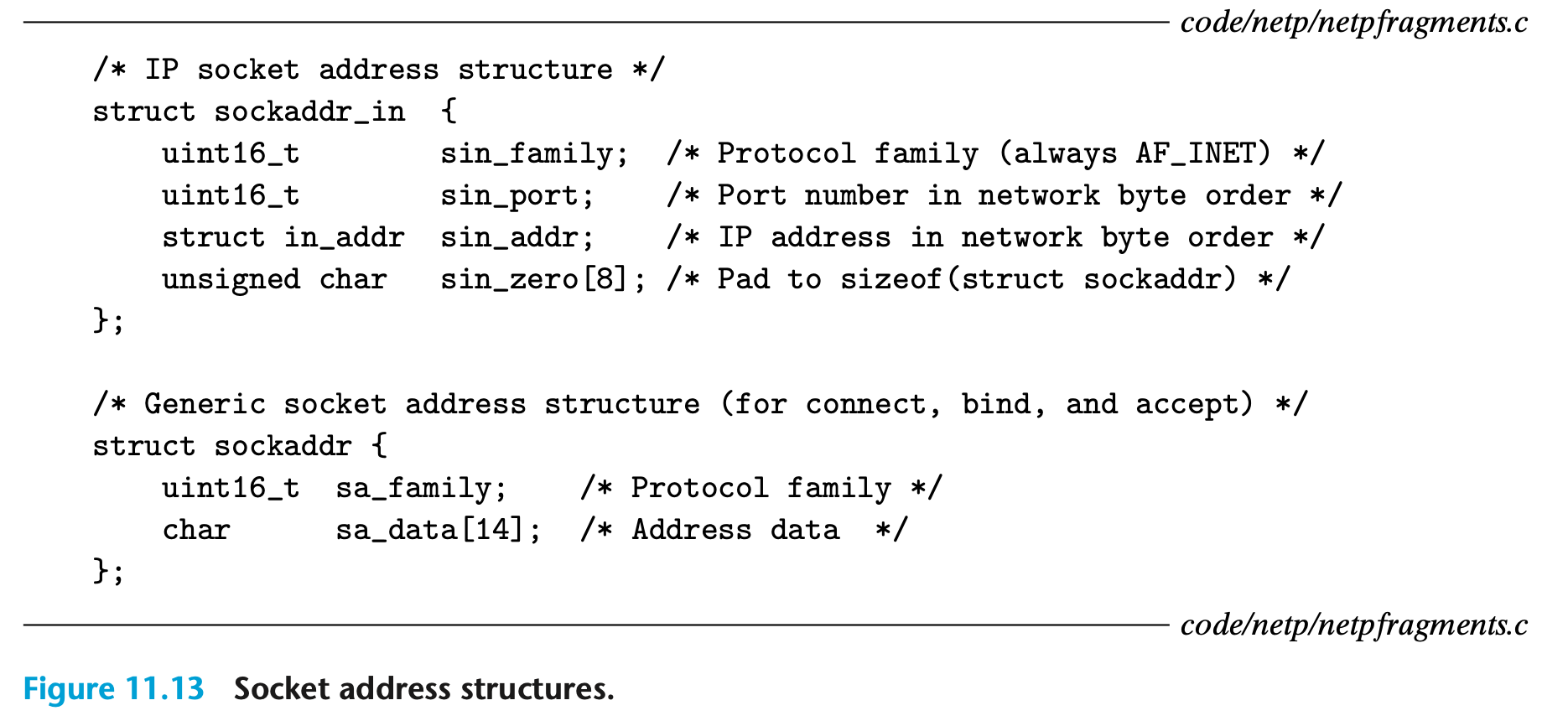
인터넷 소켓 주소는 그림 11.13에 나타난 것처럼 sockaddr_in 타입의 16바이트 구조체에 저장이 이루어진다.
- 인터넷 프로그램의 경우,
sin_family필드는AF_INET이며,sin_port필드는 16비트 포트 번호,sin_addr필드는 32비트 IP 주소를 포함한다.- IP 주소와 포트 번호는 항상 네트워크 바이트 오더(빅 엔디언)로 저장된다.
connect, bind, accept 함수들은 프로토콜에 특화된 소켓 주소 구조체에 대한 포인터를 요구한다.
- 소켓 인터페이스 설계자들이 직면한 문제는, 이러한 함수들이 어떠한 종류의 소켓 주소 구조체도 인자로 받을 수 있도록 정의하는 방법이었다.
- 오늘날에는 범용
void *포인터를 사용할 수 있지만, 당시 C에는 그런 개념이 존재하지 않았다.
- 그들의 해결책은 소켓 함수들이 범용
sockaddr구조체에 대한 포인터를 기대하도록 정의한 다음, 프로그램이 프로토콜에 특화된 구조체의 포인터를 이 범용 구조체로 형변환(cast)하도록 요구하는 것 이었다.
- 오늘날에는 범용
- 코드 예제를 단순화하기 위해, 우리는 Stevens의 방식을 따라 다음과 같이 타입을 정의 할 것이다.
typedef struct sockaddr SA;이후 필요할 때마다 sockaddr_in 구조체를 범용 sockaddr 구조체로 형변환할 때 이 SA 타입을 사용하겠다.
11.4.2 소켓 함수
클라이언트와 서버는 소켓 함수를 사용하여 소켓 디스크립터(socket descriptor)를 생성한다.
#include <sys/types.h>
#include <sys/socket.h>
int socket(int domain, int type, int protocol);반환값: 성공 시 음이 아닌 디스크립터, 오류 시 −1
예를 들어, 소켓을 연결의 끝점으로 사용하고자 한다면, 아래와 같이 하드코딩된 인자를 이용하여 호출할 수 있다:
clientfd = socket(AF_INET, SOCK_STREAM, 0);
여기서 AF_INET은 32비트 IP 주소를 사용함을 나타내고, SOCK_STREAM은 소켓이 연결의 끝점임을 의미한다.
그러나 가장 좋은 방법은 프로토콜에 독립적인 코드를 작성하기 위해, 섹션 11.4.7에서 설명하는 getaddrinfo 함수를 사용하여 이러한 인자들을 자동으로 생성하는 것이다. 섹션 11.4.8에서는 socket 함수와 함께 getaddrinfo를 사용하는 방법을 설명할 것이다.
socket 함수가 반환하는 clientfd 디스크립터는 아직 부분적으로만 열려 있으며, 읽기와 쓰기에 바로 사용할 수 없다.
소켓을 완전히 여는 방법은 클라이언트인지 서버인지에 따라 달라지며, 다음 섹션에서는 클라이언트인 경우에 소켓을 완전히 여는 방법을 설명한다.
11.4.3 connect 함수
클라이언트는 connect 함수를 호출함으로써 서버와의 연결을 수립한다.
#include <sys/socket.h>
int connect(int clientfd, const struct sockaddr *addr, socklen_t addrlen);반환값: 성공 시 0, 오류 시 −1
connect 함수는 addr에 명시된 소켓 주소에 위치한 서버와의 인터넷 연결을 수립하려고 시도하며, 여기서 addrlen은 sizeof(sockaddr_in)이다.
이 함수는 연결이 성공적으로 수립되거나 오류가 발생할 때까지 블록(block)된다.
Block 된다는 것의 의미가 무엇일까?
블록(block) 방식이라는 것은
connect함수를 호출하면, 그 함수가 연결이 완료되거나 실패할 때까지 호출한 프로그램의 실행 흐름(스레드나 프로세스)이 해당 함수 내부에서 멈추고 기다린다는 의미입니다.즉, 프로그램이
connect를 호출하면 연결이 성공적으로 맺어지거나 오류(예: 연결 거부, 네트워크 문제, 시간 초과 등)가 발생할 때까지 다음 코드는 실행되지 않습니다. 이로 인해connect함수 호출 시점에서 프로그램은 외부 이벤트(서버와의 연결 수립 결과)를 기다리며, 그 동안 다른 작업을 수행하지 않게 됩니다.이 방식은 동기식(synchronous) 통신 방식의 대표적인 예로, 특히 간단한 네트워크 프로그램에서는 코드가 매우 직관적으로 동작 순서를 이해할 수 있게 해줍니다. 물론, 응답 대기 시간이 길 경우 프로그램이 멈춘 것처럼 보일 수 있으므로, 이러한 경우 비동기식(non-blocking) 방식이나 멀티스레딩을 사용하는 방법도 있지만, 기본적으로
connect함수는 호출한 곳에서 결과가 나올 때까지 기다린다고 이해하시면 됩니다.
연결이 성공하면, clientfd 디스크립터는 읽기와 쓰기가 가능한 상태가 되고, 결과적인 연결은 소켓 페어(x:y, addr.sin_addr:addr.sin_port)로 특징 지어진다.
- 여기서
x는 클라이언트의 IP 주소이며,y는 클라이언트 호스트에서 클라이언트 프로세스를 고유하게 식별하는 임시 포트이다. socket함수와 마찬가지로, 연결 인자들을 제공할 때는getaddrinfo를 사용하는 것이 최선의 방법이다(섹션 11.4.8 참조).
11.4.4 bind 함수
남은 소켓 함수들—bind, listen, 그리고 accept—은 서버가 클라이언트와의 연결을 수립하기 위해 사용된다.
#include <sys/socket.h>
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);반환값: 성공 시 0, 오류 시 −1
bind 함수는 커널에게 addr에 있는 서버의 소켓 주소를 소켓 디스크립터 sockfd와 연관짓도록 요청한다.
여기서 addrlen 인자는 sizeof(sockaddr_in)이다.
socket과 connect 함수와 마찬가지로, bind의 인자들을 제공할 때는 getaddrinfo를 사용하는 것이 최선의 방법이다(섹션 11.4.8 참조).
11.4.5 listen 함수
클라이언트는 능동적으로 연결 요청을 시작하는 반면, 서버는 클라이언트로부터의 연결 요청을 수신하기 위해 수동적으로 대기한다.
기본적으로 커널은 socket 함수로 생성된 디스크립터가 연결의 클라이언트 측에 위치할 능동적인 소켓이라고 가정한다.
서버는 이 디스크립터가 클라이언트가 아닌 서버에서 사용될 것임을 커널에 알리기 위해 listen 함수를 호출한다.
#include <sys/socket.h>
int listen(int sockfd, int backlog);반환값: 성공 시 0, 오류 시 −1
listen 함수는 sockfd를 능동적인 소켓에서 클라이언트의 연결 요청을 수락할 수 있는 대기(listening) 소켓으로 변환한다.
인자 backlog는 커널이 연결 요청을 거부하기 시작하기 전에 큐에 저장할 미처리 연결 요청의 수에 대한 힌트이다.backlog 인자의 정확한 의미는 TCP/IP에 대한 보다 심도 있는 이해를 요구하지만, 일반적으로는 1,024와 같이 큰 값으로 설정한다.
11.4.6 accept 함수
서버는 클라이언트의 연결 요청을 기다리기 위해 accept 함수를 호출한다.
#include <sys/socket.h>
int accept(int listenfd, struct sockaddr *addr, int *addrlen);반환값: 성공 시 음이 아닌 연결 디스크립터, 오류 시 −1
accept 함수는 listening 디스크립터 listenfd에서 클라이언트의 연결 요청이 도착하기를 기다린 뒤, 그 연결 요청을 보낸 클라이언트의 소켓 주소를 addr에 채워 넣고, 클라이언트와 통신할 수 있는 연결 디스크립터(connected descriptor)를 반환한다. 이 연결 디스크립터를 이용해 유닉스의 I/O 함수를 사용하여 데이터를 주고받을 수 있다.
listening 디스크립터와 연결 디스크립터의 구분이 다소 헷갈릴 수 있다.
- Listening 디스크립터는 클라이언트의 연결 요청을 받기 위한 끝점 역할을 한다. 보통 서버의 수명 동안 한 번 생성되어 계속 유지된다.
- 연결 디스크립터는 클라이언트와 서버 사이에 연결이 수립될 때마다 새로 생성되며, 클라이언트의 요청을 서비스하는 동안만 존재한다.
[그림 11.14]
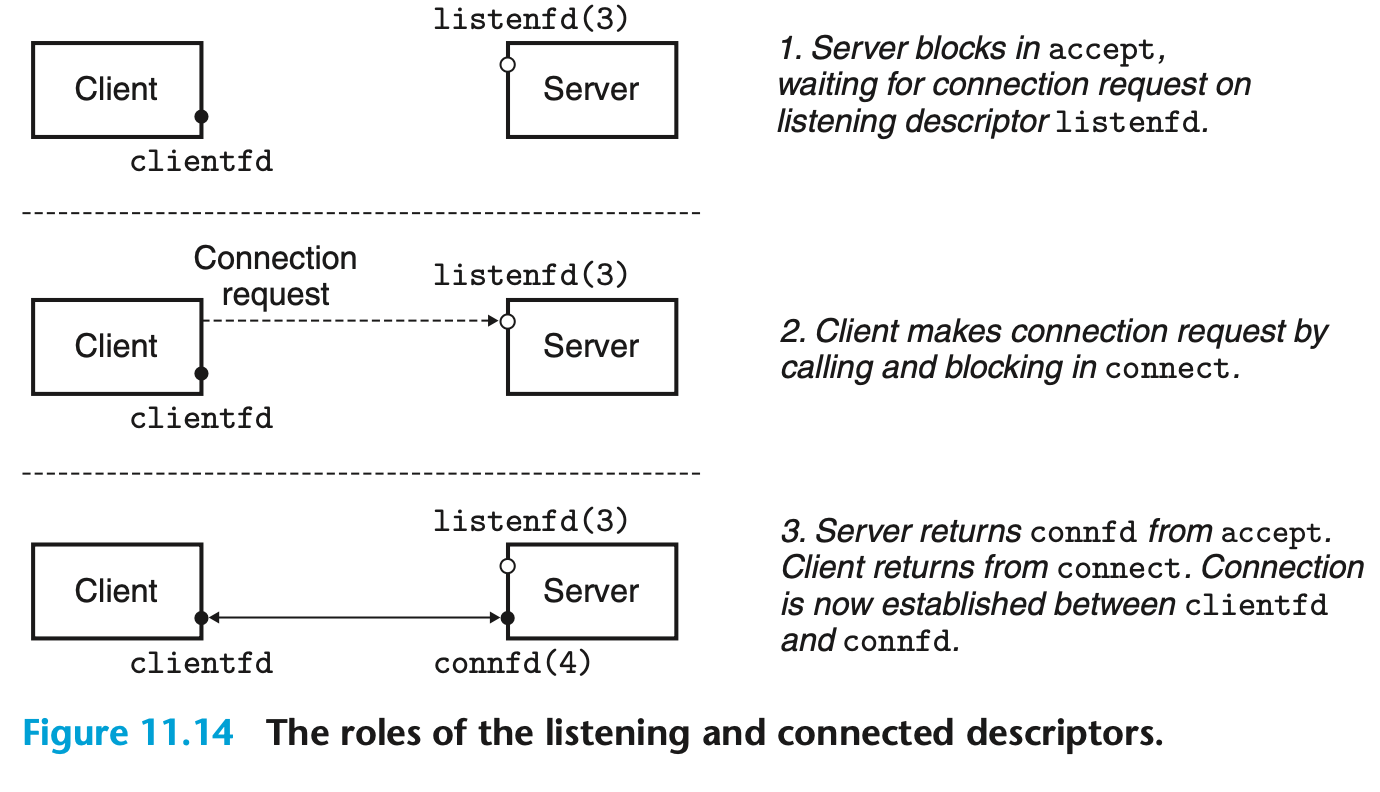
그림 11.14는 listening 디스크립터와 연결 디스크립터의 역할을 개략적으로 보여준다.
- 단계 1: 서버는
accept함수를 호출한다. 이 함수는 listening 디스크립터(구체적으로 예를 들어 디스크립터 3이라고 가정)에 연결 요청이 도착하기를 기다린다. (참고로, 디스크립터 0~2는 표준 파일에 예약되어 있다.)
- 단계 2: 클라이언트는
connect함수를 호출해 listening 디스크립터로 연결 요청을 보낸다.
- 단계 3:
accept함수는 새로운 연결 디스크립터인connfd(예를 들어 디스크립터 4라고 가정)를 열어,clientfd와connfd사이에 연결을 수립한 뒤, 이connfd를 애플리케이션에 반환한다.
클라이언트 또한 connect 호출에서 반환되며, 이 시점부터 클라이언트와 서버는 각각 clientfd와 connfd를 읽고 쓰면서 데이터를 주고받을 수 있다.
11.4.7 호스트 및 서비스 변환
Linux는 getaddrinfo와 getnameinfo라는 강력한 함수를 제공하여 이진 소켓 주소 구조체와 호스트 이름, 호스트 주소, 서비스 이름, 포트 번호의 문자열 표현 사이를 상호 변환할 수 있도록 한다. 이 함수들을 소켓 인터페이스와 함께 사용하면, 특정 IP 프로토콜 버전에 종속되지 않는 네트워크 프로그램을 작성할 수 있다.
getaddrinfo 함수
getaddrinfo 함수는 호스트 이름, 호스트 주소, 서비스 이름, 포트 번호의 문자열 표현을 소켓 주소 구조체로 변환한다.
- 이 함수는 구식의
gethostbyname및getservbyname함수의 현대적 대체 버전이다. - 이들 함수와 달리,
getaddrinfo는 재진입성을 가지며 어떠한 프로토콜과도 함께 동작한다.
#include <sys/types.h>
#include <sys/socket.h>
#include <netdb.h>
int getaddrinfo(const char *host, const char *service, const struct addrinfo *hints, struct addrinfo **result);
// 반환값: 성공 시 0, 오류 발생 시 0이 아닌 오류 코드void freeaddrinfo(struct addrinfo *result); // 반환값: 없음const char *gai_strerror(int errcode); // 반환값: 오류 메시지 문자열호스트와 서비스(소켓 주소의 두 구성 요소)를 입력받으면, getaddrinfo는 호스트와 서비스에 해당하는 소켓 주소 구조체를 가리키는 addrinfo 구조체들의 연결 리스트를 반환한다(그림 11.15 참조).
[그림 11.15]
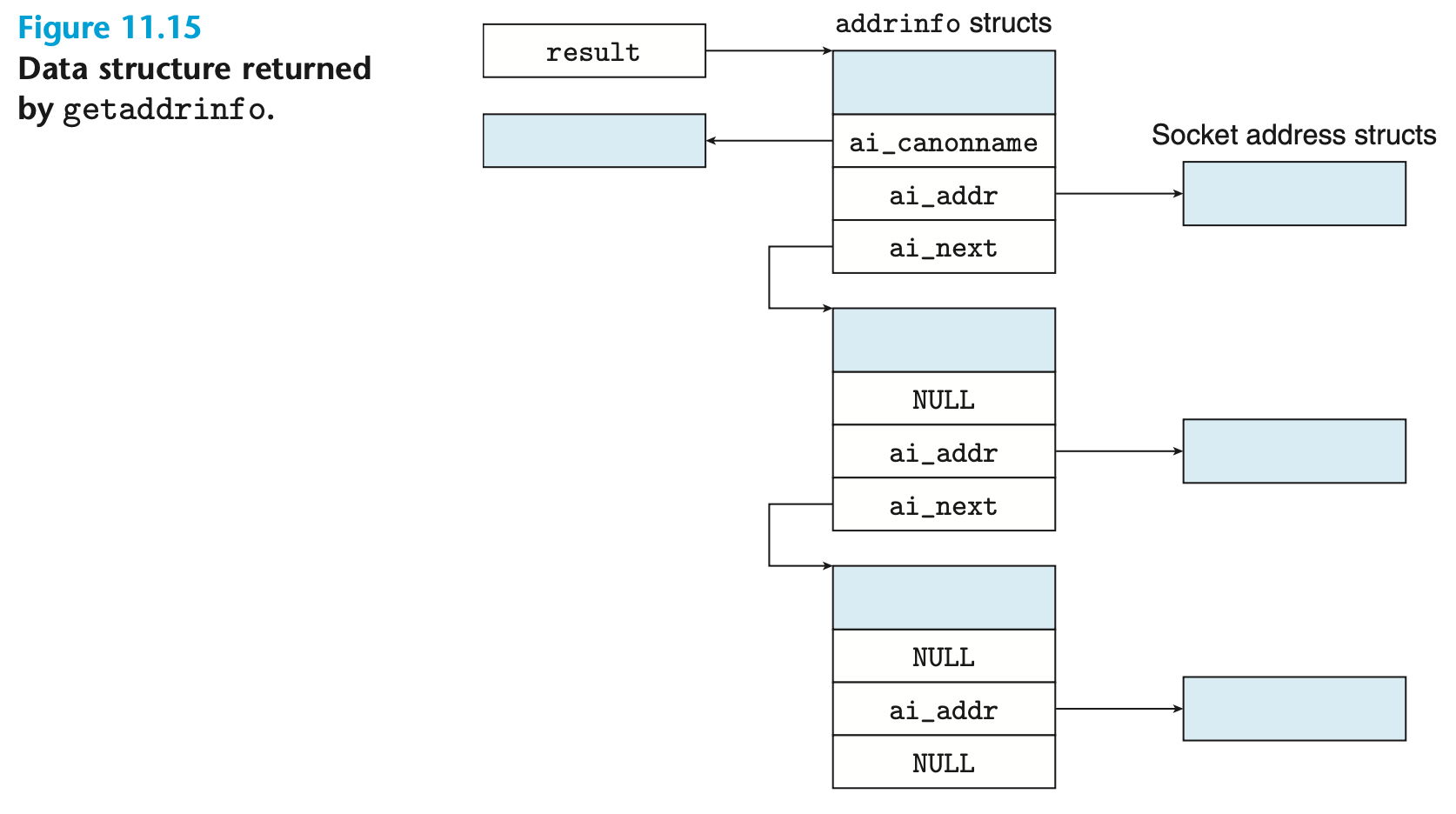
클라이언트가 getaddrinfo를 호출한 후에는 이 리스트를 순회하면서, 각 소켓 주소에 대해 socket과 connect 호출이 성공해 연결이 수립될 때까지 시도한다. 마찬가지로, 서버는 리스트의 각 소켓 주소에 대해 socket과 bind 호출을 시도하여 디스크립터가 유효한 소켓 주소에 바인딩될 때까지 진행한다.
메모리 누수를 방지하기 위해, 애플리케이션은 나중에 freeaddrinfo를 호출해 이 리스트를 해제해야 한다.
만약 getaddrinfo가 0이 아닌 오류 코드를 반환하면, 애플리케이션은 gai_strerror를 호출해 해당 오류 코드를 메시지 문자열로 변환할 수 있다.
getaddrinfo의 host 인자는 도메인 이름이나 숫자 주소(예: 도트-십진법 IP 주소)일 수 있으며, service 인자는 서비스 이름(예: "http")이나 십진수 포트 번호일 수 있다. 만약 호스트 이름을 주소로 변환할 필요가 없다면 host에 NULL을 전달할 수 있고, 서비스도 마찬가지이다. 단, 둘 중 적어도 하나는 지정되어야 한다.
[그림 11.16]

선택적 hints 인자는 addrinfo 구조체(그림 11.16)로, getaddrinfo가 반환하는 소켓 주소 리스트에 대해 보다 세밀한 제어를 제공한다. hints 인자로 전달할 때는 오직 ai_family, ai_socktype, ai_protocol, 그리고 ai_flags 필드만 설정 가능하다.
- 나머지 필드들은 반드시 0(또는 NULL)으로 설정해야 한다.
- 실제로는
memset을 사용하여 전체 구조체를 0으로 초기화한 후, 몇몇 선택된 필드를 설정한다.
기본적으로 getaddrinfo는 IPv4와 IPv6 소켓 주소 모두를 반환할 수 있다.
- 만약
ai_family를AF_INET으로 설정하면 IPv4 주소로,AF_INET6으로 설정하면 IPv6 주소로 리스트가 제한된다.
또한, 기본적으로 호스트와 연관된 각 고유 주소에 대해 getaddrinfo는 서로 다른 ai_socktype 필드를 가진 최대 세 개의 addrinfo 구조체(연결용, 데이터그램용(다루지 않음), 원시 소켓용(다루지 않음))를 반환할 수 있다. 만약 ai_socktype을 SOCK_STREAM으로 설정하면, 각 고유 주소에 대해 연결의 끝점으로 사용할 수 있는 단 하나의 addrinfo 구조체만 반환하도록 제한된다. 이는 모든 예제 프로그램에서 원하는 동작이다.
ai_flags 필드는 기본 동작을 추가로 수정하는 비트 마스크이다. 여러 값을 OR 연산하여 조합하며, 아래와 같이 유용한 옵션들이 있다:
- AI_ADDRCONFIG
- 이 플래그는 연결을 사용하는 경우 권장된다. 로컬 호스트가 IPv4로 구성되어 있으면 IPv4 주소만, IPv6로 구성되어 있으면 IPv6 주소만 반환하도록
getaddrinfo에 요청한다.
- 이 플래그는 연결을 사용하는 경우 권장된다. 로컬 호스트가 IPv4로 구성되어 있으면 IPv4 주소만, IPv6로 구성되어 있으면 IPv6 주소만 반환하도록
- AI_CANONNAME
- 기본적으로
ai_canonname필드는 NULL이다. 이 플래그가 설정되면, 리스트의 첫 번째addrinfo구조체 내ai_canonname필드를 호스트의 정식(공식) 이름으로 채우도록getaddrinfo에 지시한다(그림 11.15 참조).
- 기본적으로
- AI_NUMERICSERV
- 기본적으로
service인자는 서비스 이름이나 포트 번호가 될 수 있다. 이 플래그는service인자가 반드시 포트 번호여야 함을 강제한다.
- 기본적으로
- AI_PASSIVE
- 기본적으로
getaddrinfo는 클라이언트가connect호출에서 사용할 수 있는 능동적 소켓 주소를 반환한다.이 경우,host인자는 NULL이어야 하며, 결과 소켓 주소 구조체 내의 주소 필드는 와일드카드 주소가 되어,
- 기본적으로
- 커널에 이 서버가 해당 호스트의 모든 IP 주소에 대해 요청을 수락함을 알린다. 이는 모든 예제 서버에서 원하는 동작이다.
- 이 플래그가 설정되면, 서버가 수신 연결용(listening socket)으로 사용할 수 있는 소켓 주소를 반환하도록 지시한다.
getaddrinfo가 출력 리스트에 addrinfo 구조체를 생성할 때, ai_flags 필드를 제외한 모든 필드를 채운다. 구체적으로,
ai_addr필드는 소켓 주소 구조체를 가리키며,ai_addrlen필드는 그 소켓 주소 구조체의 크기를 나타내고,ai_next필드는 리스트 내의 다음 addrinfo 구조체를 가리킨다.
나머지 필드들은 소켓 주소의 다양한 속성을 설명한다.
getaddrinfo의 우아한 점 중 하나는, addrinfo 구조체의 필드들이 불투명(opaque)하다는 것이다.
즉, 애플리케이션 코드에서 추가 조작 없이 이 구조체의 필드들을 소켓 인터페이스 함수에 직접 전달할 수 있다.
예를 들어, ai_family, ai_socktype, ai_protocol은 그대로 socket 함수에 전달될 수 있고, ai_addr와 ai_addrlen은 그대로 connect 및 bind 함수에 전달될 수 있다. 이러한 강력한 특성 덕분에, 우리는 특정 IP 프로토콜 버전에 종속되지 않는 클라이언트와 서버를 작성할 수 있다.
getnameinfo 함수
getnameinfo 함수는 getaddrinfo 함수의 반대 역할을 한다.
즉, 소켓 주소 구조체를 해당하는 호스트 및 서비스 이름 문자열로 변환한다. 이 함수는 구식의 gethostbyaddr와 getservbyport 함수를 대체하며, 이들 함수와 달리 재진입성이 있고(섹션 12.7.2 참조), 프로토콜에 종속되지 않는다.
#include <netdb.h>
int getnameinfo(const struct sockaddr *sa, socklen_t salen,
char *host, size_t hostlen,
char *service, size_t servlen, int flags);
반환값:
- 성공 시 0 오류 발생 시 0이 아닌 오류 코드
여기서,
sa인자는 크기가salen바이트인 소켓 주소 구조체를 가리키며,host인자는 크기가hostlen바이트인 버퍼를,service인자는 크기가servlen바이트인 버퍼를 가리킨다.
getnameinfo 함수는 소켓 주소 구조체 sa를 해당하는 호스트와 서비스 이름 문자열로 변환하여, 이 문자열들을 host와 service 버퍼에 복사한다. 만약 getnameinfo가 0이 아닌 오류 코드를 반환하면, 애플리케이션은 gai_strerror를 호출하여 해당 오류 코드를 에러 메시지 문자열로 변환할 수 있다.
만약 호스트 이름이 필요하지 않다면, host를 NULL로, hostlen을 0으로 설정할 수 있다. 서비스 문자열 역시 동일하게 처리할 수 있으나, 둘 중 하나는 반드시 지정되어야 한다.
flags 인자는 기본 동작을 수정하는 비트 마스크이다. 여러 값을 OR 연산으로 조합하여 생성할 수 있으며, 유용한 플래그는 다음과 같다:
- NI_NUMERICHOST기본적으로
getnameinfo는host버퍼에 도메인 이름을 반환하려고 시도하지만, 이 플래그를 설정하면 숫자 주소(예: 도트-십진법 문자열)를 반환하게 된다.
- NI_NUMERICSERV기본적으로
getnameinfo는/etc/services파일을 참조하여 가능한 경우 포트 번호 대신 서비스 이름을 반환하지만, 이 플래그를 설정하면 조회를 건너뛰고 단순히 포트 번호를 반환하게 된다.
예제 프로그램 설명
[그림 11.17] (source)

그림 11.17은 hostinfo라는 간단한 프로그램을 보여주는데, 이 프로그램은 getaddrinfo와 getnameinfo 함수를 이용하여 도메인 이름이 어떤 IP 주소들에 매핑되어 있는지를 출력한다.
예를 들어, 도메인 이름인 twitter.com에 대해 프로그램을 실행하면, NSLOOKUP에서 보았던 것과 같이 네 개의 IP 주소가 출력된다.
linux> ./hostinfo twitter.com
199.16.156.102
199.16.156.230
199.16.156.6
199.16.156.70프로그램 흐름 요약:
- 먼저,
getaddrinfo를 호출 할 때 도메인 이름을 변환하도록host인자를 지정하고, 서비스 정보는 필요하지 않으므로NULL로 설정한다.
- 호출 후 반환된 addrinfo 구조체들의 연결 리스트를 순회하면서, 각 소켓 주소에 대해
getnameinfo를 호출하여 도트-십진법 형식의 주소 문자열로 변환한다.
- 리스트를 순회한 후에는 메모리 누수를 방지하기 위해
freeaddrinfo를 호출하여 리스트를 해제한다(단, 이 간단한 프로그램에서는 엄격하게 필요하지 않을 수도 있다).
이와 같이 getnameinfo 함수는 getaddrinfo의 역변환 역할을 수행하며, 우리가 소켓 주소를 문자열 형태로 쉽게 변환하여 인간이 읽을 수 있게 한다. 이는 네트워크 애플리케이션이 특정 IP 프로토콜 버전에 종속되지 않고 동작할 수 있도록 해주는 강력한 기능 중 하나이다.
11.4.8 소켓 인터페이스 헬퍼 함수
getaddrinfo 함수와 소켓 인터페이스는 처음 접할 때 다소 벅차게 느껴질 수 있다.
이에 클라이언트와 서버가 서로 통신할 때 편리하게 사용할 수 있도록, 저자들은 open_clientfd와 open_listenfd라는 상위 수준 헬퍼 함수로 이들을 감싸는 방식을 채택했다.
open_clientfd 함수
클라이언트는 open_clientfd 함수를 호출하여 서버와의 연결을 수립한다.
#include "csapp.h"
int open_clientfd(char *hostname, char *port);반환값:
- 성공 시: 소켓 디스크립터, 오류 시: -1
open_clientfd 함수는 주어진 hostname에서 실행 중이며 port 포트 번호에서 연결 요청을 수신하는 서버와 연결을 수립한다.
- 이 함수는 Unix I/O 함수들을 사용해 입출력이 가능한 열린 소켓 디스크립터를 반환한다.
(그림 11.18은 open_clientfd의 코드를 보여준다.)
[그림 11.18]

구현 방식은 다음과 같다:
- 먼저,
getaddrinfo를 호출하여,hostname과port에 해당하는 소켓 주소 구조체들의 연결 리스트를 얻는다.
각
addrinfo 구조체는 서버와 연결을 수립하기에 적합한 소켓 주소를 가리킨다.
- 이후, 리스트의 각 엔트리를 순차적으로 검사하며, 각각에 대해
socket과connect함수를 호출한다.- 만약
connect호출이 실패하면, 해당 소켓 디스크립터를 주의 깊게 닫은 후 다음 엔트리를 시도한다.
- 만약 연결에 성공하면, 할당된 리스트 메모리를 해제(
freeaddrinfo호출)하고 소켓 디스크립터를 반환한다.
- 만약
- 반환된 소켓 디스크립터는 즉시 Unix I/O를 사용해 서버와 데이터를 주고받을 수 있다.
특히, 소켓과 연결에 필요한 인자들은 모두 getaddrinfo에 의해 자동으로 생성되므로, 코드에는 특정 IP 프로토콜 버전에 대한 의존성이 전혀 없다. 이는 코드의 깔끔함과 이식성을 높여준다.
open_listenfd 함수
서버는 open_listenfd 함수를 호출하여 클라이언트의 연결 요청을 수신할 준비가 된 듣기 소켓(listening descriptor)을 생성한다.
#include "csapp.h"
int open_listenfd(char *port);반환값:
- 성공 시: 소켓 디스크립터, 오류 시: -1
open_listenfd 함수는 지정한 port에서 연결 요청을 기다릴 수 있는 듣기 디스크립터를 반환한다.
(그림 11.19는 open_listenfd의 코드를 보여준다.)
[그림 11.19]

구현 방식은 open_clientfd와 유사하다:
- 먼저,
getaddrinfo를 호출하여 반환된 소켓 주소 리스트를 얻는다.
- 이후, 리스트를 순회하며 각 항목에 대해
socket호출과bind호출을 시도하여 디스크립터를 소켓 주소에 바인딩한다.- 이 과정에서, 코드의 20번째 줄에서는
setsockopt함수를 사용하여 서버가 종료되거나 재시작한 후에도 즉시 연결 요청을 받을 수 있도록 설정한다. (기본적으로 재시작된 서버는 약 30초 동안 클라이언트의 연결 요청을 거부하므로, 디버깅에 큰 장애가 된다.)
- 이 과정에서, 코드의 20번째 줄에서는
getaddrinfo를AI_PASSIVE플래그와 함께 호출하고host인자를 NULL로 전달했기 때문에, 반환된 각 소켓 주소 구조체의 주소 필드는 와일드카드 주소로 설정된다. 이는 커널에 해당 서버가 호스트의 모든 IP 주소에 대한 연결 요청을 수락함을 알린다.
- 마지막으로,
listen함수를 호출하여listenfd를 듣기 디스크립터로 변환한 후, 이를 반환한다.- 만약
listen호출이 실패하면, 메모리 누수를 방지하기 위해 디스크립터를 닫은 후 에러를 반환한다.
- 만약
11.4.9 예제 에코 클라이언트와 서버


소켓 인터페이스를 배우는 가장 좋은 방법은 예제 코드를 공부하는 것이다!!
- 그림 11.20은 에코 클라이언트의 코드를 보여준다.
- 서버와 연결을 수립한 후, 클라이언트는 표준 입력으로부터 반복적으로 한 줄의 텍스트를 읽어 서버로 전송한다.
- 서버로부터 에코된(되풀이된) 한 줄의 텍스트를 읽어 표준 출력에 출력하는 루프에 들어간다.
- 이 루프는
fgets함수가 표준 입력에서 EOF(파일의 끝)를 만났을 때 종료되는데, 이는 사용자가 키보드에서 Ctrl+D를 입력했거나 리다이렉션된 입력 파일에 더 이상 텍스트 줄이 없기 때문이다.
루프가 종료된 후, 클라이언트는 소켓 디스크립터를 닫는다.
이렇게 되면 서버에 EOF 알림이 전송되고, 서버는 자신의 rio_readlineb 함수가 0을 반환하는 것을 통해 이를 감지한다.
디스크립터를 닫은 후 클라이언트는 종료된다.
클라이언트의 커널은 프로세스 종료 시 자동으로 열린 모든 디스크립터를 닫아주므로, 24번째 줄의 close 호출은 엄밀히 필요하지 않지만, 열린 모든 디스크립터를 명시적으로 닫는 것은 좋은 프로그래밍 습관이라 할 수 있다.

그림 11.21은 에코 서버의 메인 루틴을 확인 할 수 있다. 듣기 소켓(listening descriptor)을 연 후, 서버는 무한 루프에 진입한다.
각 반복(iteration)에서는 클라이언트의 연결 요청을 기다리고, 연결된 클라이언트의 도메인 이름과 포트 번호를 출력한 후, 클라이언트의 서비스를 위해 에코 함수(echo function)를 호출한다.
에코 함수가 반환되면, 메인 루틴은 연결 디스크립터(connected descriptor)를 닫습니다. 클라이언트와 서버가 각각의 디스크립터를 닫으면, 연결은 종료된다.
9번째 줄의 clientaddr 변수는 accept 함수에 전달되는 소켓 주소 구조체이다.accept가 반환되기 전에, 이 구조체는 연결 반대편에 있는 클라이언트의 소켓 주소로 채워집니다. 여기서 주목할 점은, 우리가 clientaddr을 struct sockaddr_in 대신 struct sockaddr_storage 타입으로 선언했다는 것이다.
정의상 sockaddr_storage 구조체는 모든 유형의 소켓 주소를 저장할 수 있을 만큼 크게 설계되어 있어, 코드가 특정 프로토콜에 종속되지 않도록 합니다.
또한, 이 간단한 에코 서버는 한 번에 한 클라이언트만 처리할 수 있다는 점을 주의하자. 클라이언트들을 한 번에 하나씩 순차적으로 처리하는 이러한 유형의 서버를 반복적(iterative) 서버라고 부른다. 12장에서 여러 클라이언트를 동시에 처리할 수 있는 보다 정교한 동시성(concurrent) 서버 구축 방법을 배우게 될 것이다.

마지막으로, 그림 11.22는 에코 루틴(echo routine)의 코드를 보여준다. 이 루틴은 rio_readlineb 함수가 10번째 줄에서 EOF를 만날 때까지 반복적으로 텍스트 줄을 읽고 쓰는 작업을 수행하게 된다.
11.5 웹 서버
지금까지 우리는 간단한 에코 서버를 통해 네트워크 프로그래밍을 논의했다.
이 섹션에서는 네트워크 프로그래밍의 기본 아이디어를 사용하여 작지만 꽤나 기능적인 자신만의 웹 서버를 구축하는 방법을 확인해보자.
11.5.1 웹 기본 사항
웹 클라이언트와 서버는 HTTP(하이퍼텍스트 전송 프로토콜)라는 텍스트 기반의 애플리케이션 레벨 프로토콜을 사용하여 상호 작용한다. HTTP는 단순한 프로토콜이다. 웹 클라이언트(즉, 브라우저)는 서버에 인터넷 연결을 열고 어떤 콘텐츠를 요청하며, 서버는 요청된 콘텐츠로 응답한 뒤 연결을 종료합니다. 브라우저는 이 콘텐츠를 읽어 화면에 출력한다.
FTP와 같은 전통적인 파일 검색 서비스와 웹 서비스의 가장 큰 차이점은 웹 콘텐츠가 HTML(하이퍼텍스트 마크업 언어)이라는 언어로 작성될 수 있다는 것이다. HTML 페이지는 브라우저에게 페이지 내의 다양한 텍스트와 그래픽 객체를 어떻게 표시할지를 알려주는 지시사항(태그)을 포함한다. 예를 들어, 다음 코드:
<b>Make me bold!</b>
는 브라우저에게 <b>와 </b> 태그 사이의 텍스트를 굵게 출력하라고 지시한다.
하지만 HTML의 진정한 강점은 페이지가 임의의 인터넷 호스트에 저장된 콘텐츠에 대한 포인터(하이퍼링크)를 포함할 수 있다는 점이다. 예를 들어, 다음과 같은 HTML 코드는:
<a href="<http://www.cmu.edu/index.html>">Carnegie Mellon</a>
브라우저에게 'Carnegie Mellon'이라는 텍스트 객체를 강조 표시하고, CMU 웹 서버에 저장된 index.html 파일로의 하이퍼링크를 생성하도록 한다. 사용자가 이 강조된 텍스트를 클릭하면, 브라우저는 CMU 서버로부터 해당 HTML 파일을 요청하여 화면에 표시한다.
11.5.2 웹 콘텐츠

웹 클라이언트와 서버에게 콘텐츠란, 관련된 MIME(다목적 인터넷 메일 확장) 타입과 함께 전달되는 바이트의 연속이다.
그림 11.23은 몇 가지 일반적인 MIME 타입을 보여준다.
웹 서버는 클라이언트에게 콘텐츠를 두 가지 방식으로 제공한다.
- 정적 콘텐츠:디스크 파일을 읽어 그 내용을 클라이언트에게 반환하는 방식인데, 이 경우 디스크 파일이 정적 콘텐츠(static content)가 되며, 파일을 클라이언트에게 전달하는 과정을 정적 콘텐츠 제공(serving static content)이라고 한다.
- 동적 콘텐츠:실행 파일(executable file)을 실행하여 그 출력 결과를 클라이언트에게 반환하는 방식이다. 실행 시점에 생성된 출력 내용은 동적 콘텐츠(dynamic content)라고 하며, 프로그램을 실행하여 출력 결과를 클라이언트에게 반환하는 과정을 동적 콘텐츠 제공(serving dynamic content)이라고 부른다.
웹 서버가 반환하는 모든 콘텐츠에는 관리되는 파일이 연관되어 있다. 이 파일 각각은 URL(유니버설 리소스 로케이터)이라고 불리는 고유한 이름을 가지고 있다. 예를 들어, 다음 URL:
<http://www.google.com:80/index.html>은 포트 80에서 요청을 수신하는 웹 서버가 관리하는, 인터넷 호스트 www.google.com의 /index.html이라는 HTML 파일을 식별한다. 포트 번호는 선택 사항이며, 기본적으로 잘 알려진 HTTP 포트 80이 사용된다. 실행 파일에 대한 URL은 파일명 뒤에 프로그램 인수가 포함될 수 있다. 파일명과 인수는 ‘?’ 문자로 구분되며, 각 인수는 ‘&’ 문자로 분리된다. 예를 들어, 다음 URL:
<http://bluefish.ics.cs.cmu.edu:8000/cgi-bin/adder?15000&213>은 /cgi-bin/adder라는 실행 파일을 식별하며, 이 실행 파일은 두 개의 인수 문자열 “15000”과 “213”을 인자로 받아 호출된다.
클라이언트와 서버는 트랜잭션 과정에서 URL의 서로 다른 부분들을 사용한다. 예를 들어, 클라이언트는
<http://www.google.com:80>와 같은 접두사(prefix)를 사용하여 어떤 종류의 서버에 접속할지, 그 서버가 어디에 있으며 어떤 포트에서 대기하고 있는지 등을 결정한다. 반면에, 서버는 URL의 접미사(suffix)
/index.html를 사용하여 파일 시스템 상의 파일을 찾고, 요청이 정적 콘텐츠에 해당하는지 동적 콘텐츠에 해당하는지를 결정하게 된다.
URL의 접미사 해석에 대해 이해해야 할 몇 가지 사항이 있다.
- 정적/동적 콘텐츠 구분 규칙:URL이 정적 콘텐츠에 해당하는지 동적 콘텐츠에 해당하는지를 결정하는 표준 규칙은 없다. 각 서버는 자신이 관리하는 파일에 대해 고유한 규칙을 가지고 있다. 전통적인(오래된) 방식은 모든 실행 파일이 있어야 하는 디렉토리(예:
cgi-bin)를 지정하는 것이다.
- 접미사의 초기 ‘/’:접미사에 있는 처음의 ‘/’는 Linux의 루트 디렉토리를 나타내는 것이 아니라, 요청되는 콘텐츠의 홈 디렉토리를 나타낸다. 예를 들어, 한 서버는 모든 정적 콘텐츠를
/usr/httpd/html디렉토리에, 모든 동적 콘텐츠를/usr/httpd/cgi-bin디렉토리에 저장하도록 설정 할 수도 있다.
- 최소 URL 접미사:최소한의 URL 접미사는 ‘/’ 문자 하나이다. 모든 서버는 이 ‘/’를 기본 홈 페이지(예:
/index.html)로 확장한다. 이 때문에 브라우저에 단순히 도메인 이름만 입력해도 사이트의 홈페이지를 가져올 수 있다. 브라우저는 누락된 ‘/’를 URL에 추가하여 서버에 전달하고, 서버는 이 ‘/’를 기본 파일명으로 확장한다.
11.5.3 HTTP 트랜잭션

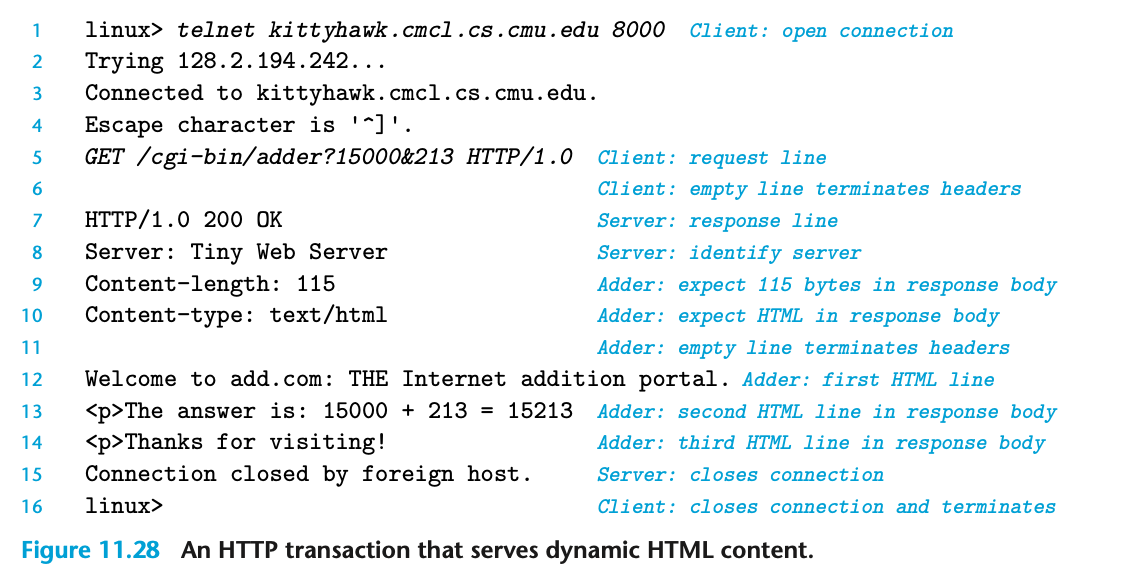
HTTP는 인터넷 연결을 통해 전송되는 텍스트 라인을 기반으로 하므로, Linux의 telnet 프로그램을 사용하여 인터넷상의 어떤 웹 서버와도 트랜잭션을 수행할 수 있다. 비록 원격 로그인 도구로서는 ssh가 telnet을 대부분 대체했지만, 텍스트 라인을 통해 클라이언트와 통신하는 서버를 디버깅할 때 telnet은 여전히 유용하다. 예를 들어, 그림 11.24에서는 AOL 웹 서버로부터 홈 페이지를 요청하기 위해 telnet을 사용하는 모습을 보여주고 있다.
- 예시 설명:
- 첫 번째 줄에서는 Linux 셸에서
telnet을 실행하며 AOL 웹 서버에 연결을 요청한다.
telnet은 터미널에 세 줄의 출력을 표시한 후 연결을 열고, 우리가 텍스트를 입력하기를 기다린다.(예: 5번째 줄)
- 우리가 텍스트 라인을 입력하고 엔터 키를 누를 때마다,
telnet은 그 라인을 읽고 캐리지 리턴과 라인 피드 문자('\\r\\n', C 표기법)를 덧붙여 서버로 전송한다. 이는 HTTP 표준에 부합하는데, HTTP는 모든 텍스트 라인이 캐리지 리턴과 라인 피드 쌍으로 종료되어야 한다고 규정하고 있다.
- 트랜잭션을 시작하기 위해, 우리는 HTTP 요청을 입력한다.(5~7번째 줄)
- 서버는 HTTP 응답을 보내고(8~17번째 줄), 그 후 연결을 종료한다.(18번째 줄)
- 첫 번째 줄에서는 Linux 셸에서
HTTP 요청
HTTP 요청은 다음과 같이 구성된다 :
- 요청 라인: (예: 5번째 줄)요청 라인은 아래와 같은 형식을 가진다
HTTP는 GET, POST, OPTIONS, HEAD, PUT, DELETE, TRACE 등 여러 메서드를 지원한다.method URI version- 하지만,여기서는 대다수의 HTTP 요청을 차지하는 GET 메서드만 다룬다.
GET 메서드는 서버에게 URI(Uniform Resource Identifier)로 지정된 콘텐츠를 생성하여 반환하도록 명령한다. - URI는 해당 URL의 접미사로, 파일명과 선택적 인수를 포함한다.
요청 라인의version필드는 요청이 준수하는 HTTP 버전을 나타낸다.
최신 HTTP 버전은 HTTP/1.1이며, 보다 단순한 이전 버전인 HTTP/1.0은 1996년에 나온 버전이다. - HTTP/1.1은 캐싱이나 보안 같은 고급 기능에 대한 지원과, 클라이언트와 서버가 동일한 지속 연결(persistent connection)상에서 여러 트랜잭션을 수행할 수 있는 메커니즘을 정의한다.
실제로 HTTP/1.0 클라이언트와 서버는 HTTP/1.1에서 추가된 헤더를 단순히 무시하므로 두 버전은 호환됩니다.
- 하지만,여기서는 대다수의 HTTP 요청을 차지하는 GET 메서드만 다룬다.
- 요약하면, 5번째 줄의 요청 라인은 서버에게
/index.htmlHTML 파일을 가져와 반환할 것을 요청하며, 이후 요청 데이터가 HTTP/1.1 형식임을 서버에 알린다.
- 요청 헤더: (예: 6번째 줄)요청 헤더는 추가적인 정보를 서버에 제공한다.
예를 들어, 브라우저의 브랜드명이나 브라우저가 이해할 수 있는 MIME 타입 등이 이에 해당한다. 요청 헤더는 아래와 같은 형식을 가집니다.
여기서 우리가 특히 주목해야 할 헤더는 HTTP/1.1 요청에서 반드시 포함되어야 하는 Host 헤더(6번째 줄)이다.header-name: header-data
Host 헤더는 프록시 캐시(proxy cache)에서 사용되는데, 프록시 캐시는 브라우저와 요청 파일을 관리하는 원본 서버(origin server) 사이의 중개자로 동작할 때가 있다. 클라이언트와 원본 서버 사이에 프록시 체인이 존재할 수 있으며, Host 헤더에 포함된 원본 서버의 도메인 이름 정보는 중간에 위치한 프록시가 요청된 콘텐츠의 로컬 캐시 사본이 있는지 확인하는 데 도움을 준다.
- 빈 텍스트 라인: (예: 7번째 줄)키보드에서 엔터 키를 눌러 생성된 이 빈 텍스트 라인은 헤더 목록의 끝을 표시하며, 서버에 요청된 HTML 파일을 전송하도록 지시한다.
HTTP 응답
HTTP 응답은 HTTP 요청과 유사하게 구성된다. HTTP 응답은 다음과 같이 이루어진다.
- 응답 라인: (예: 8번째 줄)응답 라인은 아래와 같은 형식을 가진다
version status-code status-messageversion필드는 응답이 준수하는 HTTP 버전을 나타낸다.status-code는 요청의 처리 결과를 나타내는 세 자리의 양의 정수이며,status-message는 해당 상태 코드를 영어로 설명하는 메시지이다.

응답 헤더: (예: 9~13번째 줄)응답 헤더는 응답에 관한 추가 정보를 제공하는데, 여기서 중요한 헤더 두 가지를 알아두자.
- Content-Type (12번째 줄): 응답 본문에 포함된 콘텐츠의 MIME 타입을 클라이언트에게 알려준다.
- Content-Length (13번째 줄): 응답 본문의 바이트 단위 크기를 나타낸다.
- 빈 텍스트 라인: (예: 14번째 줄)응답 헤더의 끝을 나타내는 이 빈 라인 다음에는 응답 본문이 온다.
- 응답 본문: (예: 15~17번째 줄)응답 본문에는 클라이언트가 요청한 콘텐츠가 포함되어 있다.
11.5.4 동적 콘텐츠 제공
서버가 클라이언트에게 동적 콘텐츠를 제공하는 방식을 잠시 생각해 보면, 몇 가지 의문이 제기된다. 예를 들어:
- 클라이언트는 프로그램 인수를 서버에 어떻게 전달하는가?
- GET 요청의 인수들은 URI 내에 포함된다. 앞서 본 것처럼, 파일 이름과 인수는 ‘?’ 문자로 구분되고, 각각의 인수는 ‘&’ 문자로 분리된다. 공백은 허용되지 않으며 반드시
%20과 같이 인코딩되어야 하며, 기타 특수 문자들 또한 비슷한 방식으로 인코딩된다.
- GET 요청의 인수들은 URI 내에 포함된다. 앞서 본 것처럼, 파일 이름과 인수는 ‘?’ 문자로 구분되고, 각각의 인수는 ‘&’ 문자로 분리된다. 공백은 허용되지 않으며 반드시
- 서버는 이 인수들을 자식 프로세스에게 어떻게 전달하는가?
- 서버가 아래와 같은 요청을 수신했다고 가정해보자.
서버는fork()를 호출하여 자식 프로세스를 생성한 후, 자식 프로세스의 컨텍스트 내에서/cgi-bin/adder프로그램을 실행하기 위해execve()를 호출한다. 이때, 자식 프로세스는 CGI 프로그램처럼 동작하며,execve()호출 전에 환경 변수QUERY_STRING을"15000&213"로 설정해둔다. CGI 프로그램은 실행 시, Linux의getenv함수를 통해 이 환경 변수에 접근하여 인수 값을 얻습니다.GET /cgi-bin/adder?15000&213 HTTP/1.1
- 서버가 아래와 같은 요청을 수신했다고 가정해보자.
- 서버는 동적 콘텐츠 생성을 위해 다른 정보를 자식에게 어떻게 전달하는가?
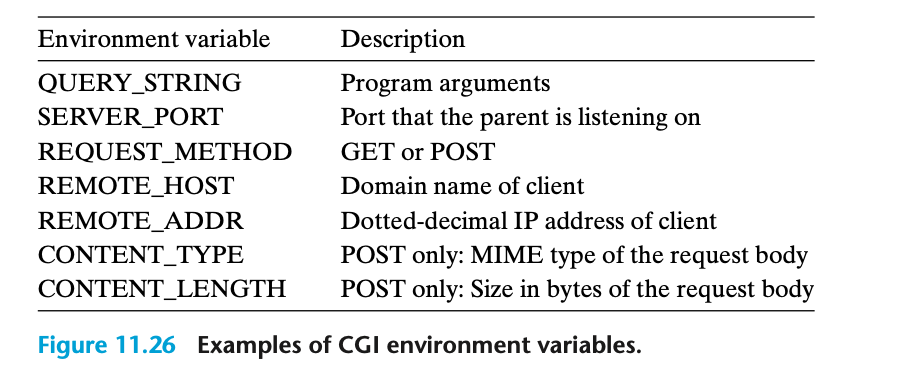
- CGI 표준은
QUERY_STRING이외에도 여러 환경 변수를 정의한다. 그림 11.26에서는 CGI 프로그램이 실행될 때 자동으로 설정되는 여러 환경 변수들의 일부를 볼 수 있다. 이 변수들은 서버에 의해 미리 설정되며, 자식 프로세스(즉, CGI 프로그램)는 이를 이용해 필요한 정보를 얻어 동적 콘텐츠를 생성할 수 있다.
- CGI 표준은
- 자식 프로세스는 자신의 출력(동적 콘텐츠)을 어디로 보내는가?
- CGI 프로그램은 동적 콘텐츠를 표준 출력(standard output)을 통해 보낸다. 자식 프로세스가 CGI 프로그램을 로드하고 실행하기 전에, 서버는 Linux의
dup2함수를 사용하여 표준 출력을 클라이언트와 연결된 소켓 디스크립터로 재지향한다. 따라서, CGI 프로그램이 표준 출력에 기록하는 모든 내용이 클라이언트로 직접 전송된다.
- CGI 프로그램은 동적 콘텐츠를 표준 출력(standard output)을 통해 보낸다. 자식 프로세스가 CGI 프로그램을 로드하고 실행하기 전에, 서버는 Linux의
또한, 부모 프로세스(서버)는 자식이 생성하는 콘텐츠의 유형이나 크기를 미리 알 수 없으므로, CGI 프로그램이 응답 헤더를 완성할 책임이 있다. CGI 프로그램은 자신이 생성한 동적 콘텐츠에 대해 Content-Type과 Content-Length 응답 헤더를 생성하고, 헤더 목록의 끝을 나타내는 빈 텍스트 라인도 출력해야 한다.

그림 11.27은 두 인수를 합산하여 결과를 포함한 HTML 파일을 클라이언트로 반환하는 간단한 CGI 프로그램의 예시를 보여주며, 그림 11.28은 adder 프로그램을 통한 동적 콘텐츠 제공 HTTP 트랜잭션의 예시를 보여주고 있다.
11.6. 종합 설계
우리가 만들 함수는 총 7개이다.
- doit 함수
- read_requesthdrs 함수
- parse_uri 함수
- serve_static / _dynamic 함수 | 정적 또는 동적 컨텐츠를 준비한 뒤 클라이언트에 직접 전송하게 된다.
- get_filetype 함수 | 매개변수로 들어온 내용을 확인하여 filetype에 반영하도록 한다.
- clienterror 함수 | error log 출력 함수이다.
네트워크 프로그래밍에 관한 논의를 마무리하면서, 우리는 Tiny라는 작지만 실제로 동작하는 웹 서버를 개발해본다.
Tiny는 매우 흥미롭다. 이 프로그램은 프로세스 제어, Unix I/O, 소켓 인터페이스, 그리고 HTTP와 같이 우리가 배운 많은 아이디어를 단 250줄의 코드로 요약한다. 실제 서버가 가지는 기능성, 강인성, 보안성은 부족할지라도, 정적 콘텐츠와 동적 콘텐츠 모두를 실제 웹 브라우저에 제공할 정도로 충분히 야무지다.
Tiny 메인 루틴
그림 11.29는 Tiny의 메인 루틴을 보여준다. Tiny는 명령줄에서 지정된 포트에서 연결 요청을 대기하는 반복형(iterative) 서버이다.open_listenfd 함수를 호출하여 리스닝 소켓을 연 후, Tiny는 일반적인 무한 서버 루프를 실행한다. 이 루프에서는 반복적으로 연결 요청을 수락(32번째 줄)하고, 트랜잭션을 수행(36번째 줄)하며, 자신의 쪽 연결을 종료(37번째 줄)한다.

doit 함수
그림 11.30에 나오는 doit 함수는 한 개의 http 트랜잭션을 처리 할 수 있다.
- 먼저 요청라인을 읽고 파싱한다 (11~14번 줄)
- 요청 라인을 읽기 위해 rio_readlineb 함수를 쓰고 있음을 주목한다. Tiny는 GET 메서드만 지원한다.
- 만약 클라이언트가 POST와 같은 다른 메서드를 요청하면, 에러 미시지를 전송하고 메인 루틴으로 복귀한다. (15~19번째 줄)
- 이 때 서버는 연결을 종료하고 다음 연결 요청을 대기한다.
- 그렇지 않으면, 요청 헤더들을 읽은 후(이후 보게 될 바와 같이) 무시한다.(20번째 줄)
- 다음으로, URI를 파일 이름과(비어 있을 수도 있는) CGI 인자 문자열로 파싱하고, 요청이 정적 콘텐츠를 위한 것인지 동적 콘텐츠를 위한 것인지를 나타내는 플래그를 설정하게 된다.(23번째 줄)
- 만약 디스크에 해당 파일이 존재하지 않으면, 즉시 클라이언트에 에러 메시지를 전송하고 복귀한다.
- 마지막으로, 요청이 정적 콘텐츠를 위한 것이라면, 파일이 일반 파일인지와 읽기 권한이 있는지를 검증한다.(31번째 줄)
- 조건이 만족되면, 정적 콘텐츠를 클라이언트에 전송한다.(36번째 줄)
- 마찬가지로, 요청이 동적 콘텐츠를 위한 것이라면, 파일이 실행 가능한지를 확인한 후(39번째 줄), 조건이 맞으면 동적 콘텐츠를 전송한다.(44번째 줄)

클라이언트 에러 함수
Tiny는 실제 서버가 갖추고 있는 많은 에러 처리 기능들을 제공하지는 않는다. 그러나, 명백한 몇 가지 오류를 검사하고 이를 클라이언트에 보고하는 기능은 포함되어 있다. 그림 11.31에 나타난clienterror 함수는, 응답 라인에 적절한 상태 코드와 상태 메시지를 포함한 HTTP 응답을 클라이언트에 전송하며, 응답 본문에는 브라우저 사용자에게 오류에 대해 설명하는 HTML 파일을 포함하고 있다.
HTML 응답에서는 본문에 포함된 콘텐츠의 크기와 유형을 명시해야 함을 기억하자.
따라서, 우리는 HTML 콘텐츠를 하나의 문자열로 구성하여 그 크기를 쉽게 결정할 수 있도록 선택했다.
또한, 모든 출력에 대해 그림 10.4에 나온 robustrio_writen 함수를 사용하고 있음을 기억하자.

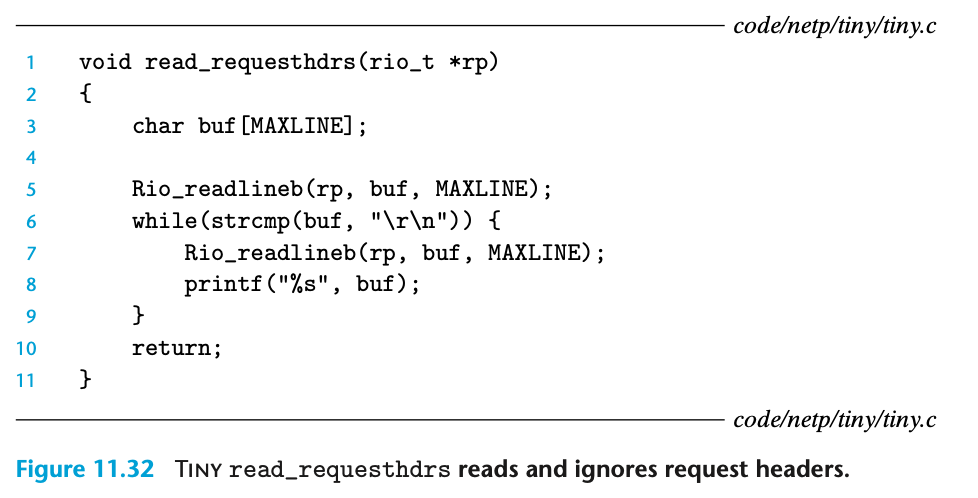
read_requesthdrs 함수
Tiny는 요청 헤더에 있는 정보들을 전혀 사용하지 않는다. 그래서, read_requesthdrs 함수를 호출하여 요청 헤더를 읽어들인 뒤 아무것도 안한다. 또한 요청 헤더의 끝을 나타내는 빈 텍스트 라인은 캐리지 리턴과 라인 피드의 쌍으로 구성되어 있음을 확인할 수 있으며, 이 부분은 6번째 줄에서 검사를 하고 있다.
parse_uri 함수
Tiny는 정적 콘텐츠의 홈 디렉토리는 현재 디렉토리로, 실행 파일의 홈 디렉토리는 ./cgi-bin으로 가정한다. URI에 문자열 cgi-bin이 포함되어 있다면 동적 콘텐츠 요청으로 간주한다. 기본 파일 이름은 ./home.html이다.
그림 11.33에 나오는 parse_uri 함수는 이러한 정책들을 구현한다. 이 함수는 URI를 파일 이름과 선택적인 CGI 인자 문자열로 파싱합니다. 만약 요청이 정적 콘텐츠에 해당한다면(5번째 줄), CGI 인자 문자열을 지우고(6번째 줄), URI를 ./index.html과 같은 상대 Linux 경로명으로 변환한다.(7~8번째 줄) 만약 URI가 '/' 문자로 끝난다면(9번째 줄), 기본 파일 이름을 덧붙인다.(10번째 줄). 반대로, 요청이 동적 콘텐츠에 해당한다면(13번째 줄), CGI 인자들을 추출한 후(14~20번째 줄) 나머지 URI 부분을 상대 Linux 파일 이름으로 변환한다.(21~22번째 줄)

serve_static 함수
Tiny는 다섯 가지 일반적인 정적 콘텐츠 유형을 제공한다 : HTML 파일, 서식이 없는 텍스트 파일, 그리고 GIF, PNG, JPEG 형식의 이미지이다.
그림 11.34에 나오는 serve_static 함수는 로컬 파일의 내용을 본문으로 포함한 HTTP 응답을 클라이언트에 전송한다. 먼저, 파일 이름의 접미사를 검사하여 파일 타입을 결정한다.(7번째 줄) 그런 다음, 응답 라인과 응답 헤더를 클라이언트에 전송한다.(8~13번째 줄) 여기서 빈 줄이 헤더의 끝을 나타낸다는 점에 주목하자.
다음으로, 연결된 디스크립터 fd로 요청된 파일의 내용을 복사하여 응답 본문을 전송한다. 이 코드는 다소 미묘하여 주의 깊게 살펴봐야 한다. 18번째 줄에서는 filename을 읽기 모드로 열어 파일 디스크립터를 얻는다. 19번째 줄에서는 Linux의 mmap 함수를 사용하여 요청된 파일을 가상 메모리 영역에 매핑한다. 9.8절에서 mmap에 대해 논의한 바와 같이, mmap 호출은 srcfd 파일의 처음 filesize 바이트를 srcp 주소에서 시작하는 프라이빗 읽기 전용 가상 메모리 영역에 매핑한다.
한 번 파일이 메모리에 매핑되면, 더 이상 파일 디스크립터가 필요 없으므로 파일을 닫는다.(20번째 줄) 이를 닫지 않으면 치명적인 메모리 누수가 발생할 수 있기 때문이다. 21번째 줄에서는 파일을 클라이언트로 실제 전송하는 역할을 수행한다. rio_writen 함수는 srcp에서 시작하는 filesize 바이트(물론 요청된 파일에 매핑된)가 클라이언트의 연결 디스크립터로 복사되도록 한다. 마지막으로, 22번째 줄에서는 매핑된 가상 메모리 영역을 해제한다. 이는 잠재적으로 치명적인 메모리 누수를 방지하는 데 매우 중요하다.

serve_dynamic 함수
Tiny는 자식 프로세스를 포크(fork)한 후, 그 자식의 컨텍스트에서 CGI 프로그램을 실행하여 모든 종류의 동적 콘텐츠를 제공한다.
그림 11.35에 나오는 serve_dynamic 함수는 우선 클라이언트에게 성공을 나타내는 응답 라인과 추가적인 정보가 담긴 Server 헤더를 전송하는 것으로 시작한다. 이후 CGI 프로그램이 응답의 나머지 부분을 전송하게 된다. 여기서 CGI 프로그램이 에러를 만날 가능성을 처리하지 않으므로, 우리가 바라는 만큼 견고하지 않다는 점에 주의하자.
첫 번째 응답 부분을 전송한 후, 새로운 자식 프로세스를 포크한다.(11번째 줄) 자식 프로세스는 요청 URI에서 전달된 CGI 인자들로 QUERY_STRING 환경 변수를 초기화한다.(13번째 줄) 실제 서버에서는 다른 CGI 환경 변수들도 이 시점에 설정했겠지만, 간결함을 위해 이 단계는 생략하였다.
다음으로, 자식 프로세스는 자신의 표준 출력을 연결된 파일 디스크립터로 리다이렉션한 후(14번째 줄), CGI 프로그램을 로드하여 실행한다.(15번째 줄) CGI 프로그램은 자식 프로세스의 컨텍스트에서 실행되므로, execve 호출 이전에 존재했던 동일한 열린 파일들과 환경 변수들에 접근할 수 있다. 따라서 CGI 프로그램이 표준 출력으로 작성하는 모든 내용은 부모 프로세스의 개입 없이 바로 클라이언트 프로세스로 전송된다. 한편, 부모 프로세스는 wait 호출로 자식 프로세스가 종료될 때까지 대기한다.(17번째 줄)
